讲讲 List、Set、Map 三大集合接口的主要区别
好的,我们来详细讲解一下 Java 集合框架中 List、Set 和 Map 这三大核心接口的主要区别。
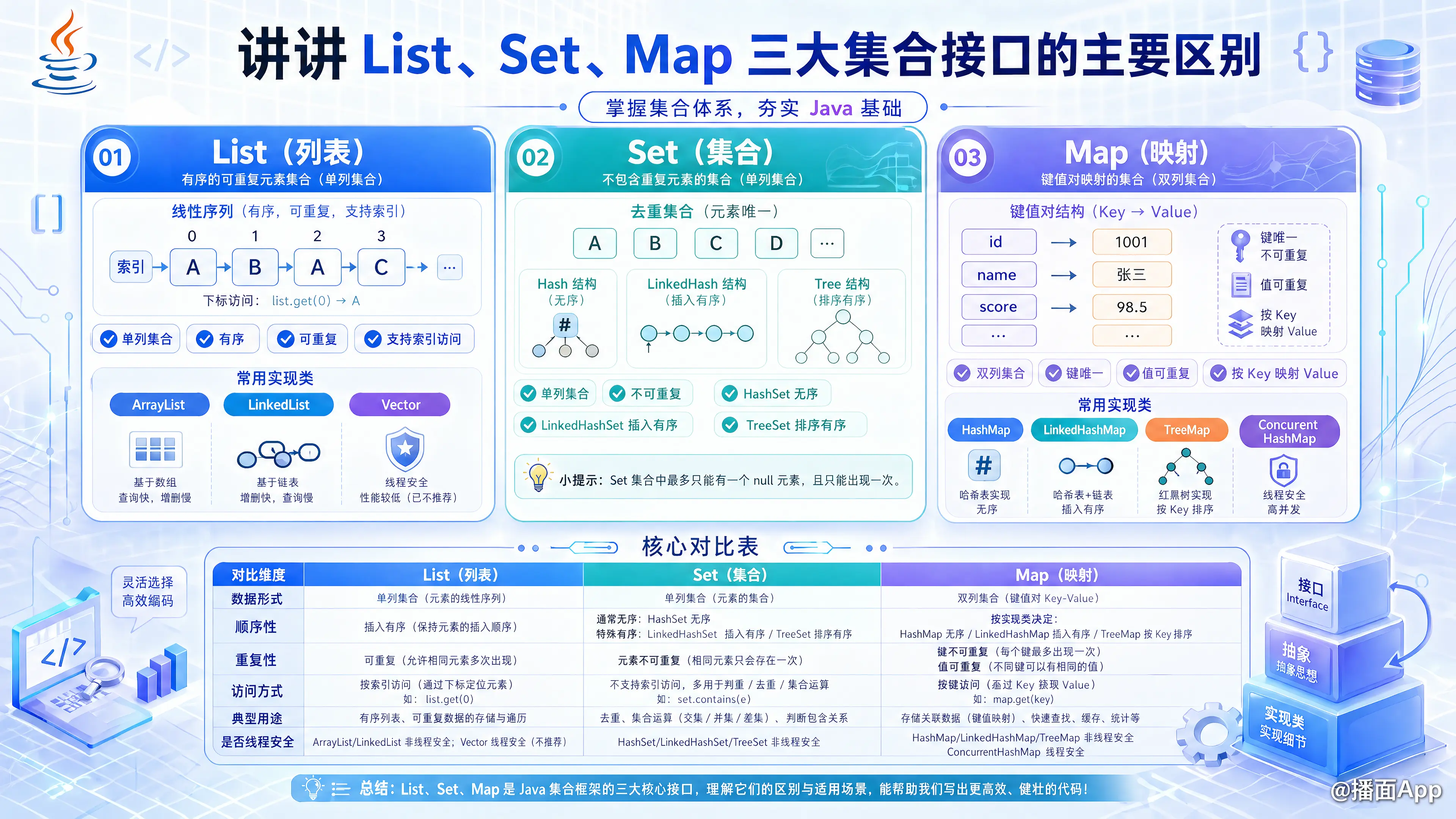
理解它们的关键在于抓住一个核心:它们存储数据的方式和结构完全不同。
- List 和 Set:属于 单列集合,它们存储的是单个的、独立的对象。
- Map:属于 双列集合,它存储的是一组组的“键值对”(Key-Value Pairs)。
下面我们从多个维度进行对比。
一、核心概念与结构对比
| 特性 | List(列表) | Set(集) | Map(映射) |
|---|---|---|---|
| 继承关系 | Collection 的子接口 |
Collection 的子接口 |
自成一派,继承自 Object,与 Collection 平级 |
| 数据形式 | 单列集合,存储一系列独立的元素。 | 单列集合,存储一系列独立的元素。 | 双列集合,存储一系列的“键-值”对。 |
| 核心特点 | 有序、可重复的集合。允许有多个相同的元素,并且元素的插入顺序会被保留。 | 无序、不可重复(或根据实现类决定唯一性)的集合。最多只能包含一个 null。 | 键唯一、值可重复。每个键最多映射到一个值。键最多只能有一个 null(取决于具体实现)。 |
| 常用实现类 | ArrayList, LinkedList, Vector, Stack (已过时) |
HashSet, LinkedHashSet, TreeSet |
HashMap, LinkedHashMap, Hashtable, ConcurrentHashMap, TreeMap |
二、详细区别解析
1. List - “有序的可重复序列”
- 有序性:这里的“序”指的是元素的插入顺序。当你遍历一个 List(如 ArrayList),你看到的元素顺序就是你添加进去的顺序。
ArrayList和LinkedList都保证这一点。- 例外:
SortedSet(如 TreeSet)是有序的,但那是按自然排序或比较器排序,不是插入顺序。
- 例外:
- 可重复性:同一个对象可以被多次添加到 List 中。
list.add("A"); list.add("A"); // "A"会出现两次 - 索引访问:List 最大的特点是可以通过整数索引(下标)来精确访问和操作元素,就像数组一样。
get(int index),add(int index, E element)。 - 典型用途:
- 需要保持元素添加顺序的场景(如记录操作日志)。
- 需要频繁通过位置查找元素的场景(
ArrayList)。 - 需要实现栈、队列等数据结构(
LinkedList)。
2. Set - “独一无二的无序/特殊序集”
- 不可重复性:这是 Set 的核心契约。不能包含两个相等的元素(根据 equals()方法判断)。如果尝试添加一个已存在的对象,
add()方法会返回 false。 - 无序性:标准的 HashSet不保证任何特定的迭代顺序,它的顺序是内部哈希算法决定的,不保证是插入顺序。
- 特殊的有序实现:
- LinkedHashSet:在 HashSet的基础上维护了一个双向链表,保证了元素的插入顺序。
- TreeSet:基于红黑树实现,保证了元素处于排序状态(自然排序或定制排序)。
- null值:大多数 Set的实现只允许一个 null元素(
HashSet、LinkedHashSet),而 TreeSet不允许 null(因为需要比较)。 - 典型用途:
- 需要确保数据唯一性的场景(如用户注册时检查用户名是否已存在)。
- 进行数学上的集合运算(并集、交集、差集)(使用 TreeSet更方便)。
- 不需要关心顺序的快速去重。
####3. Map - “键值对的映射表”
- 键值对结构:这是它与 List/Set最根本的区别。每个条目都是一个 Entry<K, V>对象,包含 Key和 Value两部分。
- 键的唯一性:Map中的所有 Key必须是唯一的。如果用一个已存在的 Key放入新的 Value,
put()方法会用新 Value覆盖旧 Value并返回旧的 Value。(这与数学中的函数 f(x) = y非常相似) - 值的重复性:Value可以重复。不同的 Key可以映射到相同的 Value上。
map.put("k1", "v"); map.put("k2", "v"); // v出现了两次 - 无序性与有序性:
- HashMap:不保证映射的顺序,特别是它不保证该顺序恒久不变。
- LinkedHashMap:维护了一个运行于所有条目的双向链表,保证了键值对的插入顺序或访问顺序。
- TreeMap:基于红黑树,保证了所有的 Key处于排序状态。
- 性能关键点:Map的性能主要取决于两个因素:Key的 HashCode()方法的实现质量(对于 HashMap/Hashtable/LinkedHashMap)和是否需要进行排序操作(对于 TreeMap)。
- 典型用途**:
- 需要通过一个唯一标识快速查找对应数据的场景(如字典:
map.get(“apple”) -> “苹果”)。 - 缓存系统(
key: userId, value: UserObject)。 - 配置信息存储。
- 需要通过一个唯一标识快速查找对应数据的场景(如字典:
###三、如何选择?
选择哪个接口和实现类,取决于你的业务需求:
- 我是否需要按照特定顺序排列?或者我是否需要经常通过位置来访问?
->如果需要位置和顺序 ->选 *List (ArrayList)
->如果只是需要保持插入时的先后顺序 ->选 LinkedHashSet / LinkedHashMap
->如果需要自动排序 ->选 TreeSet / TreeMap
2.我的数据是唯一的吗?我是否需要防止重复?->如果是且只需要存单一对象 ->选 Set (HashSet)->如果不是且可能有很多重复项 ->选 List (ArrayList)
3.我的数据是否天然具有“标识-内容”的关系?(例如 ID->用户信息)->如果是这种 key-value模型 ->毫不犹豫地选择 Map (HashMap)
4.我对线程安全有要求吗?->如果没有并发问题,ArrayList、HashSet、HashMap。->如果有并发写的需求,Vector(老式)、Collections.synchronizedXXX()包装类、ConcurrentHashMap(推荐用于高并发)、CopyOnWriteArrayXXX系列。
###总结比喻
为了帮助你记忆:
- List像一个队伍或一个购物清单**:每个人有自己的位置编号(索引),同一个人可以排好几次队(可重复),队伍的顺序就是加入时的样子(有序)。
- Set像一个会员俱乐部:会员ID(equals/hashCode)是唯一的,不能有两个完全相同的会员(不可重复)。俱乐部本身不关心谁先入会(默认无序),但有的俱乐部会按入会时间排队(LinkedHashSet),有的会按姓氏笔画排座位(TreeSet)。
- Map像一本字典或一个电话簿**:通过一个独一无二的单词(Key)去查它的解释(Value)。同一个解释可以被很多不同的单词引用(值可重复),但你不能用两个不同的单词指向同一个页码并期望得到不同结果——后者会覆盖前者(Key必须唯一)。
希望这个详细的对比能帮助你彻底理解这三者的区别!
右滑查看面试常问