如何合理地评估和配置线程池的核心线程数与最大线程数?(结合 CPU 密集型任务与 I/O 密集型任务说明)
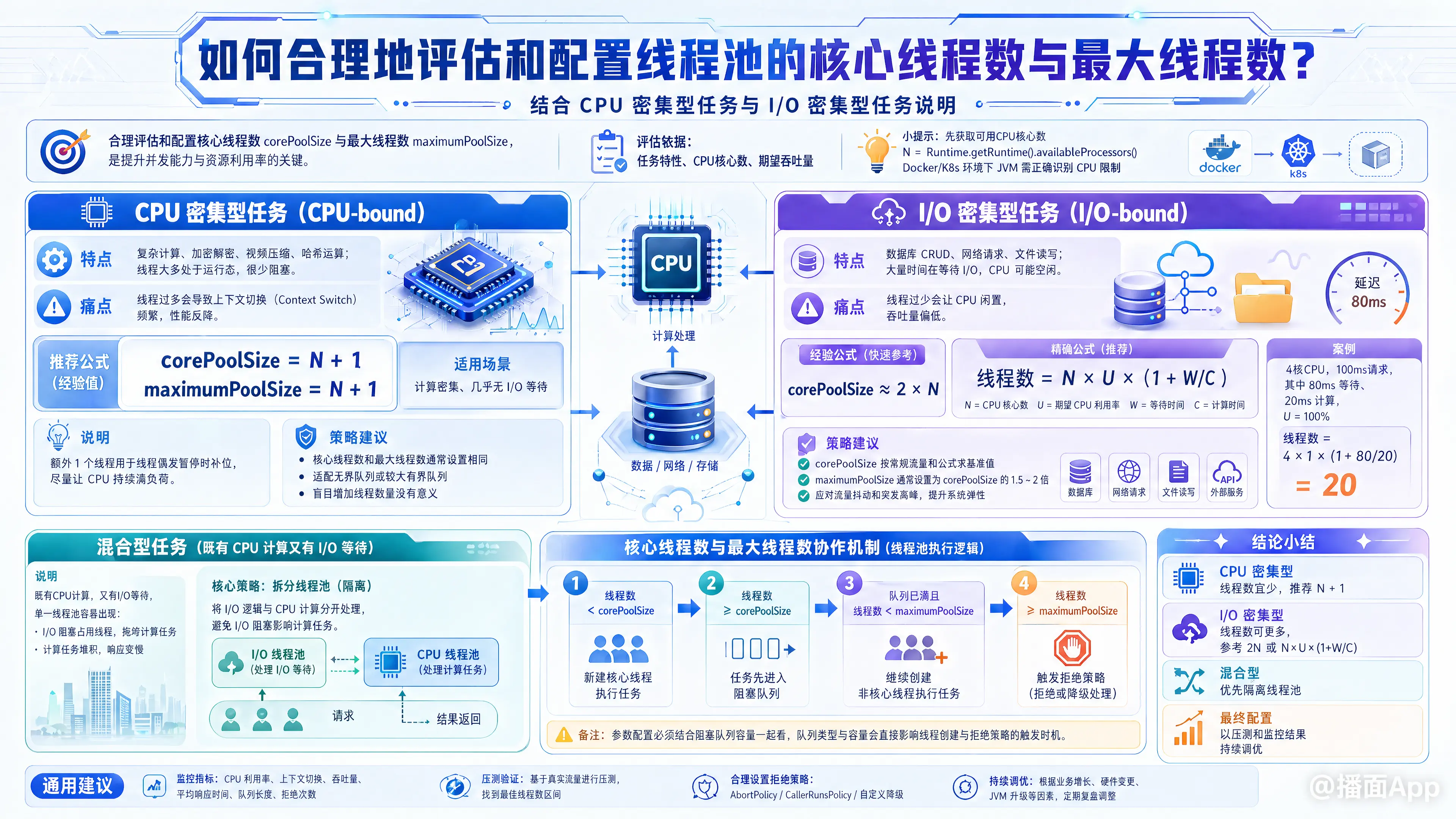
合理评估和配置线程池的核心线程数(corePoolSize)与最大线程数(maximumPoolSize)是提升系统并发能力和资源利用率的关键。
评估的标准通常基于任务的特性(CPU 密集型 vs I/O 密集型)、硬件资源(CPU 核心数)以及期望的系统吞吐量。
以下是详细的评估与配置指南:
一、 理论基础:根据任务类型配置
在配置之前,首先需要获取服务器的可用 CPU 核心数():int N = Runtime.getRuntime().availableProcessors();
(注意:在 Docker/K8s 环境下,需确保 JVM 能正确读取容器的 CPU 限制,Java 8u191 以后默认支持)
1. CPU 密集型任务 (CPU-bound)
- 特点: 任务主要消耗 CPU 资源进行计算(如:复杂数学计算、加密解密、视频压缩、哈希运算等)。线程基本处于运行状态,很少阻塞。
- 核心痛点: 线程过多会导致频繁的上下文切换(Context Switch),反而会降低系统性能。
- 配置公式:
corePoolSize=maximumPoolSize=
- 为什么是 N + 1?
额外的 1 个线程是为了防止某个运行中的线程因为缺页中断(Page Fault)或偶尔的硬件原因发生暂停时,这个额外的线程能够顶上,保证 CPU 时刻处于全负荷工作状态。 - 配置策略: 通常将核心线程数和最大线程数设置为相同,且配合无界队列或容量较大的有界队列,因为增加线程数毫无意义,只会增加切换开销。
2. I/O 密集型任务 (I/O-bound)
- 特点: 任务大部分时间在等待 I/O 操作完成(如:数据库 CRUD、网络请求、文件读写等)。在等待期间,CPU 是空闲的。
- 核心痛点: 线程过少会导致 CPU 大量时间处于闲置状态,系统吞吐量极低。
- 配置公式:
- 经验公式:
corePoolSize= (适用于简单的 I/O 任务) - 精确公式(Brian Goetz《Java并发编程实战》):
线程数 =- :CPU 核心数
- :期望的 CPU 利用率(0.0 ~ 1.0)
- :线程等待时间(Wait Time)
- :线程计算时间(Compute Time)
- 经验公式:
- 计算举例: 假设一个接口调用耗时 100ms,其中 80ms 在查数据库和调用 RPC(等待时间 W),20ms 在进行数据拼接(计算时间 C)。CPU 为 4 核,期望利用率 100%。
线程数 = 个线程。 - 配置策略:
corePoolSize:根据常规流量的 QPS 和上述公式计算得出一个基准值。maximumPoolSize:通常设置为corePoolSize的 1.5 倍到 2 倍,用于应对突发的 I/O 延迟抖动或流量高峰。
3. 混合型任务
- 特点: 既有较重的 CPU 计算,又有耗时的 I/O 操作。
- 配置策略: 拆分线程池(隔离)。将耗时的 I/O 逻辑和消耗 CPU 的逻辑分开,交给不同的线程池处理,从而最大化 CPU 利用率并防止 I/O 阻塞拖垮计算任务。
二、 核心线程数与最大线程数的协作机制(易错点)
配置这两个参数时,必须结合阻塞队列(WorkQueue)的特性来评估,因为它们的触发逻辑严格遵循以下顺序:
- 当活跃线程数 <
corePoolSize:直接创建新线程执行任务。 - 当活跃线程数 =
corePoolSize:新任务会被放进 阻塞队列 中排队。 - 当队列满了 且活跃线程数 <
maximumPoolSize:才会创建非核心线程(即触发最大线程数)去处理新任务。 - 当队列满了 且活跃线程数 =
maximumPoolSize:触发拒绝策略(RejectedExecutionHandler)。
实战避坑:
如果你使用了 LinkedBlockingQueue 且没有指定容量(默认是 Integer.MAX_VALUE),那么任务会无限期堆积在队列中,maximumPoolSize 参数将永远失效,永远不会有超过 corePoolSize 的线程被创建,最终可能导致 OOM。
结论:永远使用有界队列,并合理设置队列大小。
三、 实战评估与配置步骤(工程化落地)
理论公式只是起点,真正的合理配置必须经过压测和动态调整。
第一步:基准预估
根据业务场景(比如典型的 Web 服务通常是 I/O 密集型),使用 公式初步算出一个 corePoolSize(如 20),并将 maximumPoolSize 设为 40,队列大小设为 1000。
第二步:压力测试 (Stress Testing)
使用 JMeter 等工具模拟真实流量进行压测,同时监控以下指标:
- CPU 使用率: 如果 CPU 使用率长期低于 50%,说明 I/O 占比较大,可以继续调大线程数;如果 CPU 飙升到 90% 以上,且发生剧烈上下文切换(可通过
vmstat查看),说明线程数过多或计算较重,需调小线程数。 - 内存使用率: 观察是否存在 OOM 风险,评估队列的最大容量。
- 响应时间 (RT): 观察 P99 延迟,如果 RT 突然大幅变长,可能是队列堆积严重或发生了拒绝策略。
第三步:监控与动态化 (最佳实践)
在微服务架构中,硬编码线程池参数是反模式。最合理的方案是引入动态线程池机制。
- 工具推荐: 美团的动态线程池实践、开源框架
Hippo4j或DynamicTp。 - 原理: JDK 的
ThreadPoolExecutor提供了setCorePoolSize()和setMaximumPoolSize()方法。结合 Nacos/Apollo 等配置中心,可以在系统运行时,根据实时监控面板(Grafana),动态调整核心线程数和最大线程数,而无需重启服务。
四、 总结配置参照表
| 任务类型 | 核心线程数 (core) |
最大线程数 (max) |
队列类型选择 | 核心设计理念 |
|---|---|---|---|---|
| CPU 密集型 | 容量较大的有界队列 | 榨干 CPU,杜绝线程上下文切换带来的性能损耗。 | ||
| I/O 密集型 | 预估值 (如 ) | core 的 1.5~2 倍 |
合理容量的有界队列 | 以量换时间,在线程阻塞时让出 CPU,利用最大线程和队列应对突发流量。 |
| 混合型 | 拆分为两个线程池 | 拆分为两个线程池 | 按拆分后的属性定 | 隔离,避免慢 I/O 拖垮快计算。 |
一句话口诀:
CPU 密集配 N+1 减切换,I/O 密集配高倍数抗阻塞;用有界队列防 OOM,配动态调参保平安。