Transformer中有哪三种不同的Attention应用场景(Encoder中、Decoder中、Encoder-Decoder之间)
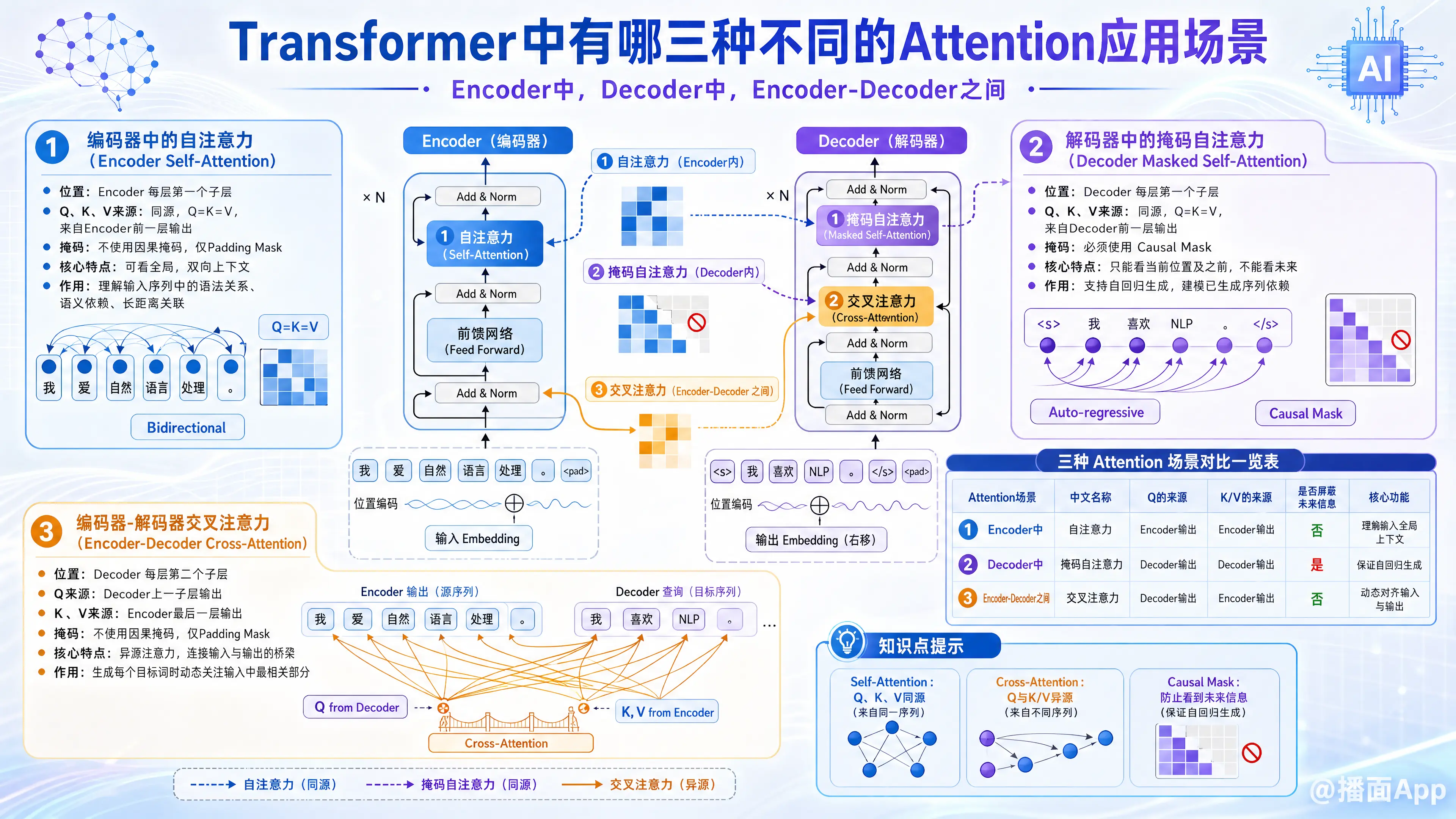
在Transformer模型中,注意力机制(Attention Mechanism)是其核心灵魂。具体来说,Transformer使用的是多头注意力(Multi-Head Attention),它通过计算查询(Query, Q)、键(Key, K)和值(Value, V)之间的映射关系来提取特征。
根据 Q、K、V 的来源以及是否使用掩码(Mask),Transformer将Attention巧妙地应用在了三个不同的场景中:
1. 编码器中的自注意力(Encoder Self-Attention)
- 位置: 位于 Encoder 的每一层中(第一个子层)。
- Q、K、V 的来源: 同源。Q、K、V 均来自 Encoder 前一层的输出(对于第一层则是输入序列的词嵌入加上位置编码)。即 。
- 掩码(Masking): 不使用因果掩码(只使用 Padding Mask 忽略填充位)。
- 作用与意义:
- 它允许输入序列中的每一个词去关注序列中的所有其他词(双向上下文)。
- 目的: 帮助模型理解输入序列中词与词之间的语法关系、语义依赖(例如指代消解)。即使两个词在句子中相隔很远,自注意力也能直接捕捉到它们的联系,从而提取出极其丰富的全局特征表示。
2. 解码器中的掩码自注意力(Decoder Masked Self-Attention)
- 位置: 位于 Decoder 的每一层中(第一个子层)。
- Q、K、V 的来源: 同源。Q、K、V 均来自 Decoder 前一层的输出(对于第一层则是目标序列的词嵌入加上位置编码)。即 。
- 掩码(Masking): 必须使用因果掩码(Causal Mask / Subsequent Mask)。
- 作用与意义:
- 在生成文本时,模型是自回归的(Auto-regressive),即必须从左到右一个词一个词地生成。
- 目的: 掩码机制确保了在预测位置 的输出时,模型只能看到位置 及其之前的词,不能“偷看”位置 之后的词(未来的信息)。它用于捕捉已生成序列内部的依赖关系。
3. 编码器-解码器之间的交叉注意力(Encoder-Decoder Cross-Attention)
- 位置: 位于 Decoder 的每一层中(第二个子层,紧跟在掩码自注意力之后)。
- Q、K、V 的来源: 异源。
- Q(Query): 来自 Decoder 中上一个子层(掩码自注意力层)的输出。代表解码器当前正在生成的内容的“需求”。
- K(Key)和 V(Value): 来自 Encoder 最后一层的输出。代表对输入序列进行全面编码后的丰富信息。
- 掩码(Masking): 不使用因果掩码(只使用 Padding Mask)。
- 作用与意义:
- 这是连接输入(Source)和输出(Target)的桥梁。
- 目的: 允许 Decoder 在生成每一个目标词时,去动态地关注(Attend to)输入序列中最相关的部分。这非常类似于人类在翻译句子时,每写下一个词,眼睛就会去扫视原文中对应的词汇。
总结对比表
为了更直观地理解,可以用下表总结这三种场景的区别:
| Attention 场景 | 中文名称 | Q 的来源 | K 和 V 的来源 | 是否屏蔽未来信息 (Causal Mask) | 核心功能 |
|---|---|---|---|---|---|
| Encoder 中 | 自注意力 (Self-Attention) | 上一层 Encoder 输出 | 上一层 Encoder 输出 | 否 (可看全局) | 理解输入序列的全局上下文和内部依赖。 |
| Decoder 中 | 掩码自注意力 (Masked Self-Attention) | 上一层 Decoder 输出 | 上一层 Decoder 输出 | 是 (只能看过去) | 理解已生成序列的上下文,防止信息穿越。 |
| Encoder-Decoder 之间 | 交叉注意力 (Cross-Attention) | Decoder 当前层 | Encoder 最终输出 | 否 (可看全局输入) | 在生成当前词时,寻找输入序列中的相关信息(对齐)。 |
右滑查看面试常问