如果 Kafka 集群中一台机器突然掉电,数据会丢失吗?
这是一个非常经典的 Kafka 面试题和生产实践问题。
简短的回答是:取决于你的 Kafka 集群和生产者的配置。
Kafka 的设计理念是通过多机副本来保证数据的可靠性,而不是依赖单机的磁盘同步(fsync)。如果配置得当,一台机器突然掉电绝对不会丢失数据;但如果使用了默认或者追求极致性能的配置,数据可能会丢失。
具体是否会丢失,我们需要从以下几个维度来详细拆解:
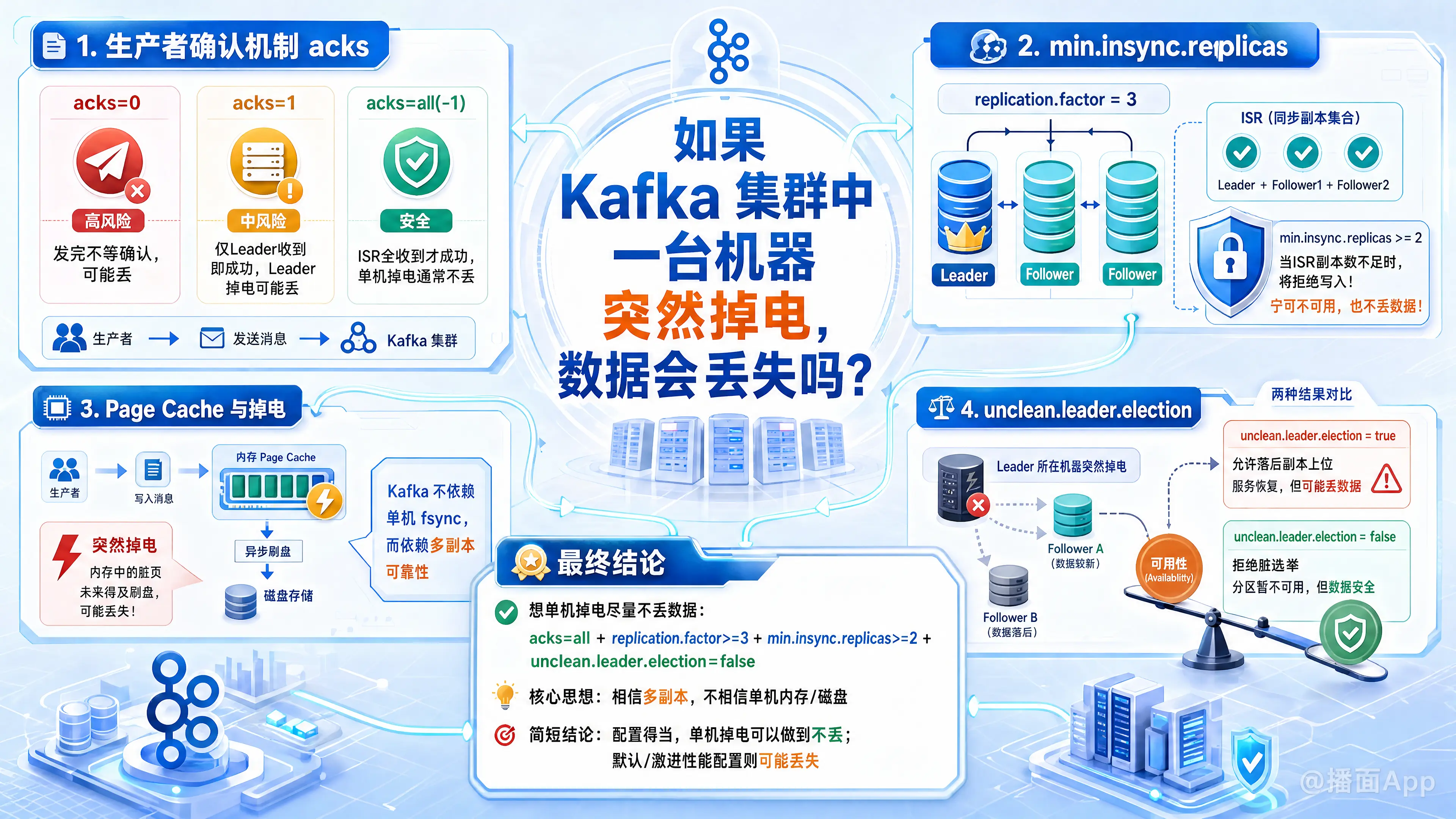
1. 生产者确认机制 (acks 配置)
这是决定数据是否丢失的最关键因素。当生产者发送消息给 Kafka 时,有一个 acks 参数:
acks = 0:生产者发完数据就不管了。如果此时数据刚发到网卡,机器就掉电了,数据丢失。acks = 1(默认值,较老版本):只要 Leader 副本所在的机器接收到数据并写入内存(Page Cache),就向生产者返回成功。如果此时 Leader 机器突然掉电,且数据还没有来得及同步给 Follower 副本,数据丢失。acks = all(或-1):Leader 必须等待所有 ISR(In-Sync Replicas,同步副本集合)中的机器都接收到数据后,才向生产者返回成功。只要 ISR 中还有存活的机器,单机掉电不会丢失数据。
2. 最小同步副本数 (min.insync.replicas)
即使你设置了 acks = all,如果配置不当,依然会丢数据。
假设你的副本因子 (replication.factor) 是 3,但是某段时间内网络抖动,另外两台 Follower 都掉线了,此时 ISR 列表里只剩下 Leader 自己。
这时候 acks = all 实际上退化成了 acks = 1。如果此时这台 Leader 机器掉电,数据依然会丢失。
- 如何防止? 必须在 Broker 或 Topic 级别设置
min.insync.replicas >= 2。这样当 ISR 列表里少于 2 台机器时,Kafka 会拒绝接收新数据,宁可牺牲可用性,也要保证不丢数据。
3. “脏页”与掉电的致命关系(Page Cache)
这是一个非常底层的细节,也是“突然掉电”这个场景最特殊的地方。
- Kafka 为了极高的吞吐量,默认情况下不会将每条消息强制刷入磁盘(调用
fsync),而是交给了操作系统的 Page Cache(内存),由操作系统决定何时刷盘。 - 掉电意味着内存中的数据瞬间清空。如果一台机器掉电,它缓存在 Page Cache 中尚未刷入磁盘的数据会全部消失。
- 那 Kafka 是怎么保证安全的? Kafka 的哲学是:我不相信单机的磁盘,我只相信多台机器的内存。 只要你配置了
acks=all和多副本,哪怕机器 A 掉电丢了内存里的数据,机器 B 和机器 C 的内存/磁盘里还有这份数据。Kafka 会迅速选举 B 或 C 成为新的 Leader,继续对外提供服务。
4. 脏 Leader 选举 (unclean.leader.election.enable)
假设一台机器掉电了,它是 Leader。此时需要选举新的 Leader。
- 如果存活的机器中,没有一台是属于 ISR(完全同步)列表里的(即剩下的机器数据落后于掉电的机器),怎么办?
- 如果
unclean.leader.election.enable = true:Kafka 会允许让落后的机器成为新 Leader。这意味着服务恢复了,但是掉电机器上多出来的那部分数据彻底丢失了。 - 如果
unclean.leader.election.enable = false(现代版本默认):Kafka 会宁死不屈,拒绝选举,导致该 Partition 不可用,直到掉电的机器重启恢复。这样不会丢失数据。
总结:如何配置才能保证单机掉电绝对不丢数据?
如果你希望在单机甚至少数几台机器掉电的情况下,数据绝对安全(银行/金融级配置),必须同时满足以下条件:
- Topic 副本数:
replication.factor >= 3(至少有 3 份数据) - 生产者配置:
acks = all(或 -1) (必须等大家都有了才算成功) - Broker/Topic 配置:
min.insync.replicas >= 2(至少有 2 台机器确认收到数据) - Broker 配置:
unclean.leader.election.enable = false(绝不允许落后的副本当 Leader)
只要满足上述 4 点,集群中一台机器突然掉电,甚至主板烧毁,你的数据也安然无恙。
右滑查看面试常问