Kafka 是如何支持“恰好一次”(Exactly-Once)语义的?
在分布式系统中,实现“恰好一次”(Exactly-Once Semantics, EOS)是非常困难的,因为网络故障、节点宕机随时可能导致消息丢失或重复。
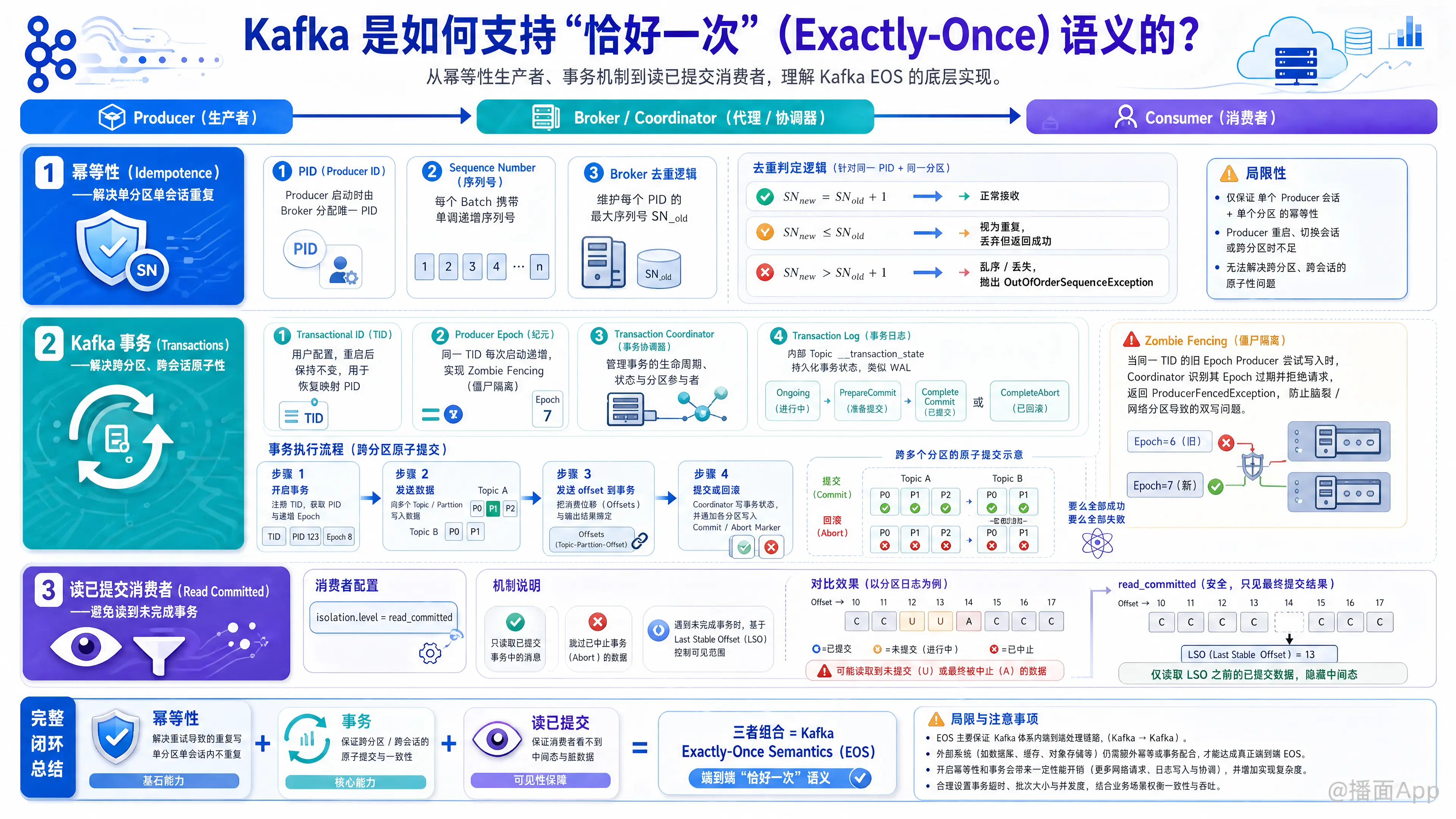
Apache Kafka 从 0.11 版本开始,正式支持了 Exactly-Once 语义。Kafka 实现这一目标的基石可以分为三个核心维度:幂等性生产者(Idempotent Producer)、事务(Transactions),以及读已提交(Read Committed)消费者。
以下是 Kafka 支持 Exactly-Once 语义的详细底层机制:
第一层:幂等性(Idempotence)—— 解决单分区单会话的重复
在没有幂等性之前,如果 Producer 发送消息到 Broker 后,网络出现闪断,Producer 没有收到 ACK,就会触发重试,从而导致 Broker 端产生重复消息。
开启方式: Producer 配置 enable.idempotence=true。
底层机制:
- PID (Producer ID): 当 Producer 启动时,Broker 会为其分配一个唯一的 PID。
- Sequence Number (序列号): Producer 发送的每一条消息(精确地说是每一个 Batch)都会带有一个单调递增的 Sequence Number。
- Broker 端的去重逻辑: Broker 的每个分区会在内存中维护每个 PID 对应的最大 Sequence Number(
SN_old)。- 当收到新消息(
SN_new)时,如果SN_new == SN_old + 1,Broker 正常接收。 - 如果
SN_new <= SN_old,说明是重复消息,Broker 直接丢弃并返回成功(防止 Producer 继续重试)。 - 如果
SN_new > SN_old + 1,说明出现了乱序或消息丢失,抛出OutOfOrderSequenceException。
- 当收到新消息(
局限性: 幂等性只能保证单个 Producer 会话、单个目标分区内的 Exactly-Once。如果 Producer 挂掉重启(PID 改变),或者要向多个分区发送消息,单纯的幂等性就无能为力了。
第二层:Kafka 事务(Transactions)—— 解决跨分区、跨会话的原子性
为了在跨多个分区、多个 Topic 写入时也能保证 Exactly-Once,并且在 Producer 重启后依然生效,Kafka 引入了事务机制。
核心组件:
- Transactional ID (TID): 由用户显式配置。TID 具有持久性,Producer 重启后 TID 保持不变。Kafka 通过 TID 来映射并恢复之前的 PID。
- Producer Epoch(纪元): 每次 Producer 使用相同的 TID 启动时,Epoch 会递增。这实现了僵尸隔离(Zombie Fencing),如果网络分区导致出现了两个相同的 Producer,Broker 只会接受 Epoch 更大的那个,旧的“僵尸”Producer 会被拒绝。
- Transaction Coordinator(事务协调器): 运行在 Broker 上的模块,负责管理事务的状态。
- Transaction Log(事务日志): 一个内部 Topic (
__transaction_state),用于持久化记录事务的状态(如 Ongoing、PrepareCommit、CompleteCommit 等),类似于数据库的 Write-Ahead Log (WAL)。
事务执行流程(两阶段提交的变种):
- 开启事务: Producer 找到 Transaction Coordinator,注册 TID,获取 PID 和递增的 Epoch。
- 发送数据: Producer 开始向各个业务分区发送数据。同时,Coordinator 会记录这个事务涉及了哪些分区。
- 提交/回滚事务: Producer 调用
commitTransaction()。- Coordinator 首先将
PrepareCommit状态写入事务日志 Topic。 - 写控制消息(Control Marker): Coordinator 向该事务涉及的所有业务分区写入一个特殊的控制消息(Commit Marker 或 Abort Marker)。这个 Marker 标识着这批消息是被提交还是废弃。
- Coordinator 将
CompleteCommit状态写入事务日志,事务结束。
- Coordinator 首先将
第三层:消费端隔离级别(Isolation Level)—— 保证消费者只读到有效数据
既然 Producer 写入了带有事务的数据,Consumer 就必须有能力辨别哪些数据是提交的,哪些是回滚的。
开启方式: Consumer 配置 isolation.level=read_committed(默认是 read_uncommitted)。
底层机制:
- LSO (Last Stable Offset): Broker 为每个分区维护一个 LSO。LSO 以下的事务要么已经 Commit,要么已经 Abort。处于开启状态的事务消息都在 LSO 之上。
- 过滤逻辑: 当 Consumer 读取数据时,Broker 只会返回 LSO 之前的数据。
- 识别 Marker: 当 Consumer 读到业务分区的消息时,如果碰到 Abort Marker,Consumer 在底层会自动丢弃该事务对应的所有消息,不会将其交给应用程序;如果碰到 Commit Marker,才会将数据交付给上层。
第四层:流处理中的“消费-处理-生产”循环 (Consume-Transform-Produce)
在实际业务(如 Kafka Streams 或 Flink)中,真正的 Exactly-Once 是指:从上游 Topic 消费一条消息,进行计算,将结果写入下游 Topic,且保证消费者位移(Offset)的提交和下游数据的写入是原子操作。
Kafka 事务完美支持了这一点,因为 消费者位移(Offset)本质上也是存储在 Kafka 内部 Topic (__consumer_offsets) 中的消息。
原子操作流程:
- 开启事务。
- 从上游 Topic 消费数据。
- 处理数据。
- 将处理结果
send()到下游 Topic。 - 最关键的一步: 调用
sendOffsetsToTransaction(),将当前消费的 Offset 作为事务的一部分,发送给 Transaction Coordinator(最终写入__consumer_offsets)。 commitTransaction()。
结果: 业务数据写入下游 Topic 和 Offset 提交变成了同一个事务。要么同时成功(消费完成且结果产出),要么同时失败(数据没写进下游,Offset 没提交,重启后重新消费)。这就实现了端到端的 Exactly-Once 语义。
总结
Kafka 的 Exactly-Once 语义是一个系统工程:
- 单分区防重: 依赖 PID 和 Sequence Number 的幂等性机制。
- 多分区原子写入: 依赖 TID、Epoch 防僵尸、Transaction Coordinator 以及两阶段提交写入 Control Marker 的事务机制。
- 端到端 Exactly-Once: 将“数据写入”和“Offset 提交”打包进同一个事务,配合消费端的
read_committed隔离级别。