Kafka 的事务消息(Transactional Message)是如何实现的?
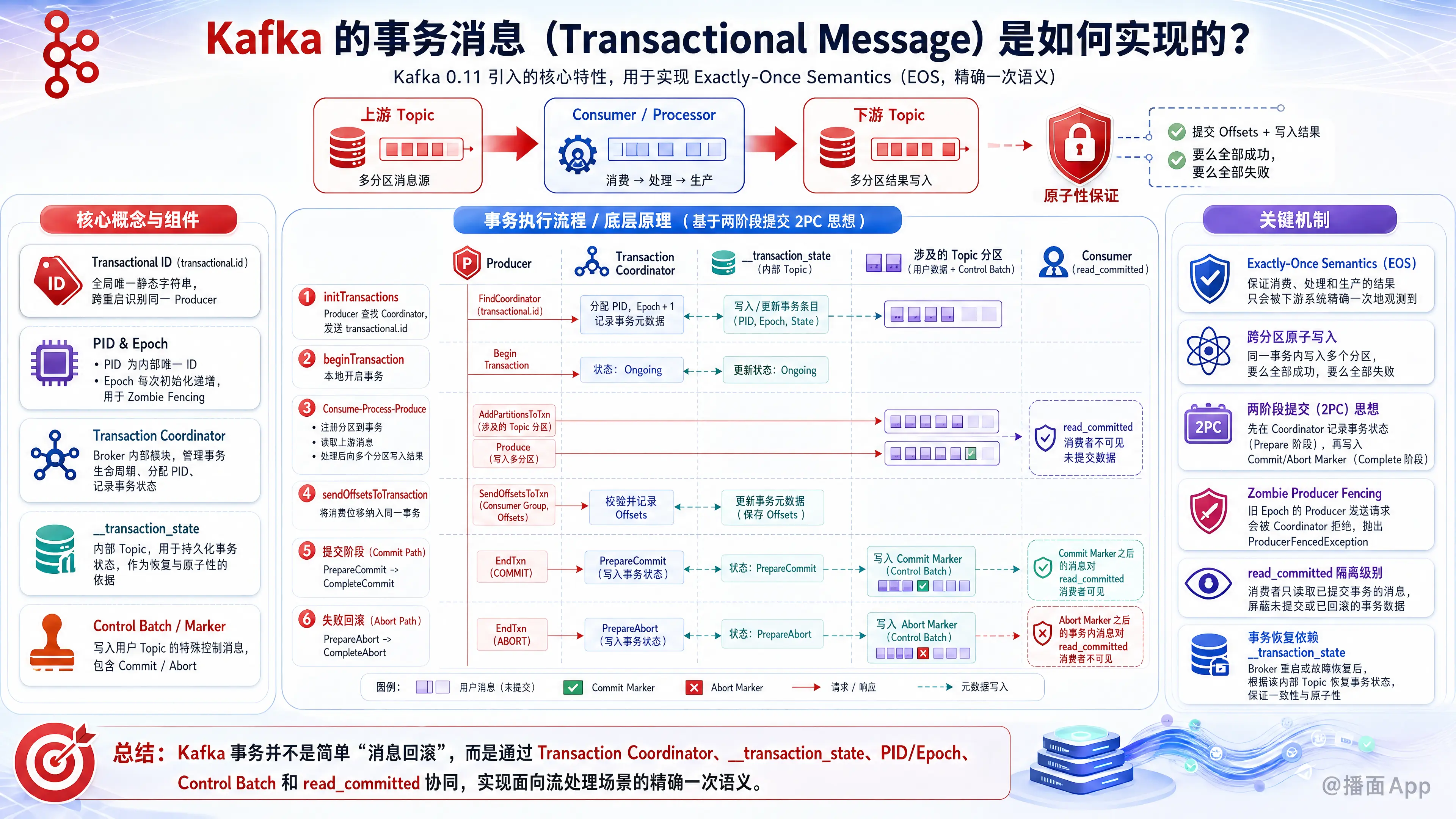
Kafka 的事务消息(Transactional Message)是在 Kafka 0.11 版本引入的核心特性,主要用于实现 Exactly-Once Semantics (EOS,精确一次语义)。
Kafka 事务最核心的场景是 “消费-处理-生产”(Read-Process-Write) 模式(例如 Kafka Streams)。它保证了从上游 Topic 读取消息、提交消费位移(Offsets)、并向下游 Topic 写入处理结果,这三个操作要么全部成功,要么全部失败,从而实现原子性跨分区写入。
下面深入拆解 Kafka 事务消息的底层实现原理。
一、 核心概念与组件
在了解流程之前,需要先认识几个关键组件和概念:
- Transactional ID (
transactional.id):- 由用户显式配置的全局唯一静态字符串。
- 作用是跨越 Producer 的重启,确保同一个 Producer 实例重启后依然能被 Kafka 识别。
- Producer ID (PID) 和 Epoch:
- PID:Kafka 集群为每个 Producer 分配的内部唯一 ID。
- Epoch(纪元):与 PID 绑定的版本号。每次 Producer 初始化时(例如重启),Epoch 都会递增(Epoch + 1)。Kafka 利用 Epoch 来防止“僵尸 Producer”(Zombie Fencing),即屏蔽旧的、因网络隔离假死后又复活的 Producer 写入数据。
- Transaction Coordinator(事务协调器):
- 运行在 Kafka Broker 内部的模块。每个
transactional.id都会被哈希分配给特定的 Transaction Coordinator。 - 负责管理事务的整个生命周期(两阶段提交)、分配 PID、记录事务状态。
- 运行在 Kafka Broker 内部的模块。每个
- Transaction Log (
__transaction_state):- Kafka 内部的特殊 Topic。由 Transaction Coordinator 独占写入。
- 用于持久化事务的状态(如
Ongoing、PrepareCommit、CompleteCommit等)。它是事务恢复和保证原子性的数据源。
- Control Batch (控制消息 / Marker):
- 这是写入到用户 Topic(数据分区)中的特殊消息。
- 对用户不可见,包含
Commit或Abort标记。消费者根据这些标记决定是否将前面的消息暴露给应用程序。
二、 事务的执行流程(底层原理解析)
Kafka 事务的实现借鉴了 两阶段提交(2PC) 的思想。一个完整的事务流程如下:
1. 初始化事务 (initTransactions)
- Producer 启动时,向任意 Broker 发送请求,查找属于自己的 Transaction Coordinator。
- Producer 向 Coordinator 发送包含
transactional.id的 Init 消息。 - Coordinator 在
__transaction_state主题中记录该 ID,为其分配 PID,并将 Epoch 递增。 - 防御僵尸(Fencing):如果此时有旧的 Producer(带着旧的 Epoch)尝试发送消息或提交事务,Broker 会拒绝请求(抛出
ProducerFencedException)。
2. 开启事务 (beginTransaction)
- 这是 Producer 本地的操作,标记事务开始,此时 Coordinator 并不知情。
3. 消费-处理-生产 (Consume - Process - Produce)
- 注册分区:当 Producer 第一次向某个 Topic-Partition 发送数据前,会先向 Coordinator 发送
AddPartitionsToTxnRequest。Coordinator 将这个“分区列表”记录到 Transaction Log 中(状态为Ongoing)。 - 写入数据:Producer 像往常一样把真实数据写入目标 Partition。这些消息被正常追加到日志中,但在消息头上带有 PID、Epoch 和事务标记。
- 注册消费位移:如果是 Stream 场景,Producer 需要提交上游的消费位移。它会向 Coordinator 发送
AddOffsetsToTxnRequest,告知 Coordinator 它要向哪个 Consumer Group 提交位移。
4. 提交或回滚事务 (commitTransaction / abortTransaction)
这是最核心的两阶段提交过程:
第一阶段:记录准备提交/回滚状态(Prepare)
- Producer 告知 Coordinator 要 Commit 或 Abort。
- Coordinator 将
PrepareCommit或PrepareAbort状态写入 Transaction Log (__transaction_state)。 - 注意:一旦写入成功,即使 Coordinator 宕机,事务最终也一定会完成(Commit 或 Abort)。
第二阶段:写入控制标记(Write Markers)
- Coordinator 根据之前记录的“分区列表”,向所有涉及的 Data Partitions 和
__consumer_offsets(位移主题)发送 Control Batch (Commit/Abort Marker)。 - Broker 收到 Marker 后,将其追加到对应分区的日志末尾。
最终阶段:完成事务(Complete)
- 所有 Marker 写入成功后,Coordinator 将
CompleteCommit或CompleteAbort状态写入 Transaction Log。事务宣告结束。
三、 消费者(Consumer)如何读取事务消息?
事务消息已经写入了 Topic,消费者如何保证只读到已提交的消息?
Kafka Consumer 有一个配置参数 isolation.level,默认是 read_uncommitted,在事务场景下必须设置为 read_committed。
在 read_committed 级别下:
- LSO (Last Stable Offset):Broker 维护了一个 LSO 指针。LSO 之前的消息都是已确定的(不在任何进行中的事务中)。Broker 只会把 LSO 之前的消息返回给 Consumer。
- 过滤 Abort 消息:Consumer 会在内部缓存拉取到的事务消息。当遇到
Commit Marker时,将缓存的消息交给应用程序;当遇到Abort Marker时,直接丢弃属于该事务的消息。 - 零额外存储开销:由于普通消息和事务消息混合存放在同一个文件里,Kafka 不需要为事务消息维护额外的存储空间,保证了极高的磁盘顺序读写性能。
四、 总结:Kafka 事务的关键设计亮点
- 高可用性:Transaction Coordinator 的状态持久化在
__transaction_stateTopic 中,该 Topic 同样有副本机制。Coordinator 宕机会触发重新选举,新 Coordinator 读取 Log 即可恢复事务状态。 - Epoch 机制解决“脑裂”:通过强制 Epoch 单调递增,优雅地解决了分布式系统中常见的“僵尸进程”问题,保证了 Exacty-Once。
- 数据和标记分离:真实数据先写入目标 Partition,最后再追加一个极小的 Marker。这使得事务不影响 Kafka 原有的吞吐量设计。
- 消费者端过滤:复杂的事务可见性逻辑主要通过 Broker 端的 LSO 和 Consumer 端的轻量级过滤实现,避免了复杂的锁机制。
右滑查看面试常问