讲讲Kafka 的多副本(Replica)机制
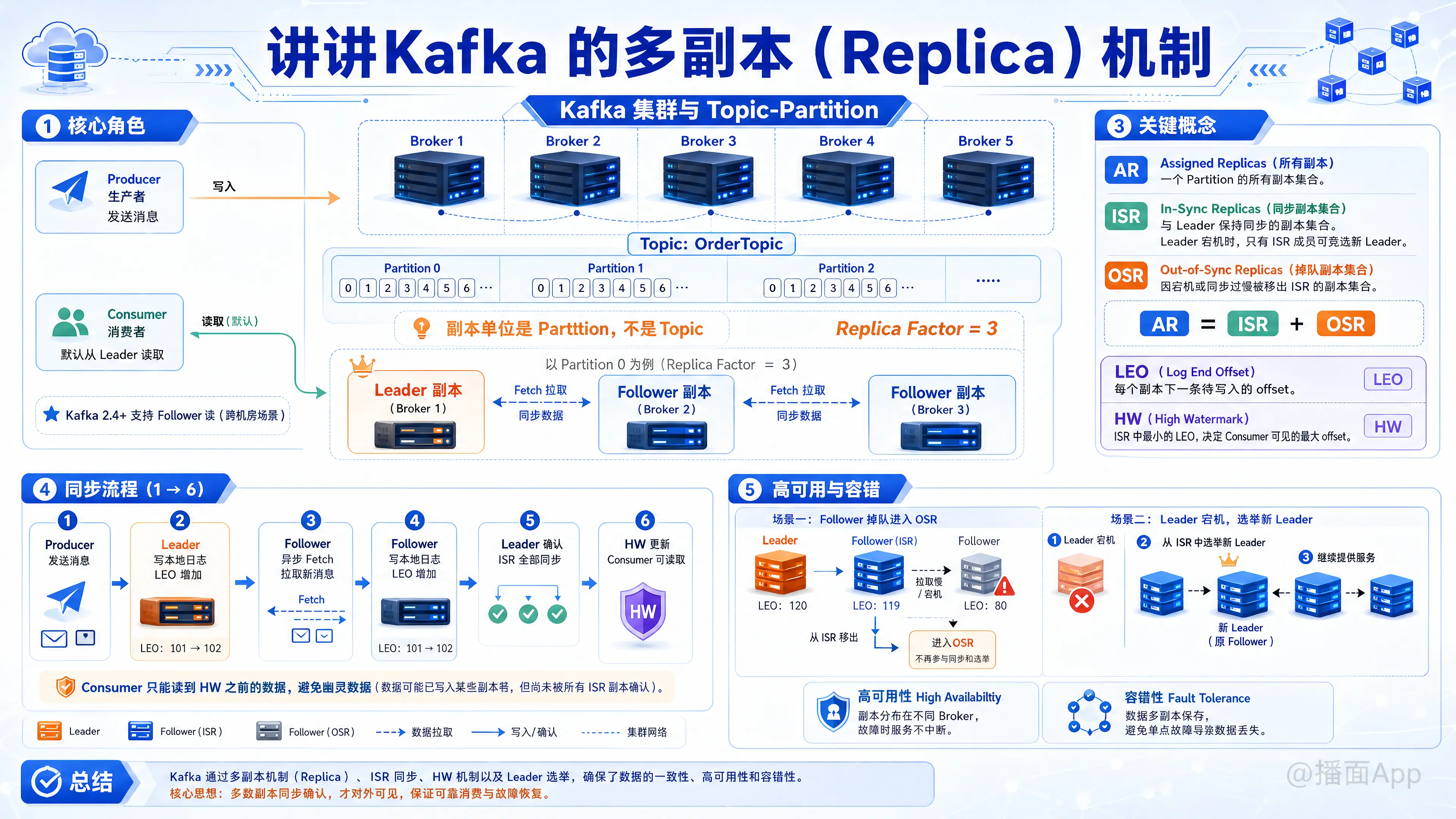
Kafka 的多副本(Replica)机制是 Kafka 实现 高可用性(High Availability) 和 容错性(Fault Tolerance) 的核心基石。简单来说,它就是把数据多复制几份存放在不同的机器上,当某一台机器宕机时,数据不会丢失,系统依然能正常提供服务。
为了让你深入且系统地理解,我们从核心角色、关键概念、同步原理、故障恢复机制这四个维度来把 Kafka 的副本机制扒得干干净净。
一、 核心角色与基本设定
在 Kafka 中,副本的单位是 Partition(分区),而不是 Topic。一个 Partition 可以有多个副本(Replica Factor,副本因子,通常设置为 3)。
这些副本被分为两类角色:
- Leader 副本(老大):
- 负责干活:处理 Producer 的所有写请求,传统情况下也处理 Consumer 的所有读请求(Kafka 2.4 之后支持从 Follower 读,但这主要为了跨数据中心省流量,默认还是 Leader 读写)。
- 只有它接收外部的请求。
- Follower 副本(小弟):
- 只做备份:不处理外部客户端的读写请求。
- 默默同步:它唯一的工作就是像 Consumer 一样,不断地向 Leader 发送拉取(Fetch)请求,把 Leader 的新数据同步到自己身上,保持与 Leader 一致。
二、 必须要懂的四个核心行话(AR, ISR, LEO, HW)
要搞懂副本机制,这四个名词是绕不开的:
1. 副本集合 (AR, ISR, OSR)
- AR (Assigned Replicas):分区的所有副本统称。
- ISR (In-Sync Replicas):同步副本集合。这是跟 Leader 保持同步的副本列表(Leader 自己也在里面)。只有在 ISR 里的副本,才有资格在 Leader 宕机时被选为新 Leader。
- OSR (Out-of-Sync Replicas):掉队副本集合。如果某个 Follower 挂了,或者同步太慢(超过
replica.lag.time.max.ms设定的时间),就会被 Leader 踢出 ISR,放入 OSR。 - 公式:AR = ISR + OSR
2. 位移标记 (LEO, HW) —— 数据一致性的关键
- LEO (Log End Offset):每个副本都有自己的 LEO。它表示该副本底层日志中下一条待写入消息的 offset(也就是当前最新消息 offset + 1)。
- HW (High Watermark,高水位):所有 ISR 集合中最小的 LEO。
- HW 的作用是限制 Consumer。Consumer 只能拉取到 HW 之前的消息。哪怕 Leader 已经接收到了新消息(LEO 增加了),只要 Follower 还没同步完(HW 没增加),这些新消息对 Consumer 就是不可见的。
- 这保证了数据一致性:就算 Leader 突然挂了,被选出的新 Leader 也一定包含了 HW 之前的所有消息,Consumer 不会读到“幽灵数据”。
三、 数据写入与同步全流程
假设一个 Partition 有 1 个 Leader 和 2 个 Follower,Producer 发送一条消息:
- Producer 将消息发给 Leader。
- Leader 将消息写入本地日志,自己的 LEO 增加。
- 两个 Follower 异步地向 Leader 发送 Fetch 请求拉取数据。
- Follower 拉取到数据后,写入本地日志,自己的 LEO 增加。
- 当 Leader 知道所有 ISR 中的 Follower 都拉取了这条消息后,Leader 就会更新整个分区的 HW(高水位线)。
- 此时,Consumer 就可以读到这条消息了。
如何保证不丢数据?(acks 参数)
Producer 发送消息时,可以配置 acks 参数来决定等待多少个副本确认:
acks = 0:发出去就不管了。速度最快,但如果 Leader 没写成功就挂了,数据丢失。acks = 1:只要 Leader 写入成功就返回成功。如果 Leader 写成功,但 Follower 还没同步,Leader 突然挂了,数据丢失。acks = all(或-1):Leader 写入成功,且 ISR 中的所有副本都同步成功,才返回成功。最安全,但性能最慢。
⚠️ 经典面试坑点:
仅仅设置acks = all就能绝对保证不丢数据吗?
不能! 如果此时 ISR 里只有 Leader 一个节点(其他小弟都掉队被踢出了),acks=all退化成了acks=1。如果 Leader 挂了,依然丢数据。
正确做法:acks=all必须配合 Broker 端参数min.insync.replicas(最小同步副本数,通常设为 2)一起使用。如果 ISR 数量小于 2,直接拒绝写入,从而保证绝对的数据安全。
四、 故障恢复机制(Leader Election)
当灾难发生时,Kafka 的副本机制是如何自救的?
1. Follower 挂了
- 该 Follower 会被踢出 ISR。
- 当它重启恢复后,它会读取本地记录的 HW,把高于 HW 的那部分数据全部截断丢弃(因为那些数据可能未被 Leader 确认,是不安全的数据)。
- 然后它开始向 Leader 请求同步,当它的 LEO 追上 Leader 时,重新加入 ISR。
2. Leader 挂了(核心机制)
- Controller(Kafka 的集群大脑)会立刻感知到 Leader 挂了。
- Controller 会从 ISR 列表 中按顺序挑选出第一个存活的 Follower,将其提拔为新的 Leader。
- 其他 Follower 发现换了新老大,会立即截断自己高于当前 HW 的数据,并开始向新 Leader 同步数据。
3. 极端情况:ISR 全军覆没(Unclean Leader Election)
如果 Leader 挂了,且此时 ISR 列表为空(所有跟得上的小弟全挂了,只剩下 OSR 里严重掉队的小弟),怎么办?
Kafka 提供了一个参数 unclean.leader.election.enable:
- 设置为
false(默认):宁为玉碎,不为瓦全。停止服务,等待原 ISR 里的副本恢复。保证数据不丢,但牺牲可用性。 - 设置为
true:矮子里拔将军。从 OSR 里选一个掉队的副本当 Leader。保证服务可用,但会丢失部分数据(因为掉队副本没有最新数据)。
五、 总结:为什么 Kafka 的副本机制设计得这么好?
- 分离读写,专注性能:与 Elasticsearch 等不同,传统 Kafka 副本只有 Leader 提供读写,Follower 绝对静默同步。这避免了分布式系统中最头疼的“一致性读”问题,Leader 不需要和其他节点加锁协商,大大提升了吞吐量。
- ISR 动态调整,兼顾延迟:传统多数派协议(如 Paxos/Raft 需要过半数同意)在有慢节点时会被拖垮。Kafka 的 ISR 机制会自动踢除慢节点,保证了
acks=all时的同步速度不会被个别网络卡顿的机器拖死。 - HW 机制,保证消费者安全:通过水位线隔离了“已提交数据”和“未提交数据”,让消费者永远处于安全的消费状态。
一句话概括 Kafka 的多副本机制:通过 Leader 集中处理读写,通过 ISR 动态管理健康备份,通过 LEO 和 HW 保证数据同步与消费一致性,最终实现了高吞吐下的高可用。