当Agent检索到的长期记忆与当前的短期记忆发生矛盾时,在上下文工程中应如何处理这种冲突?
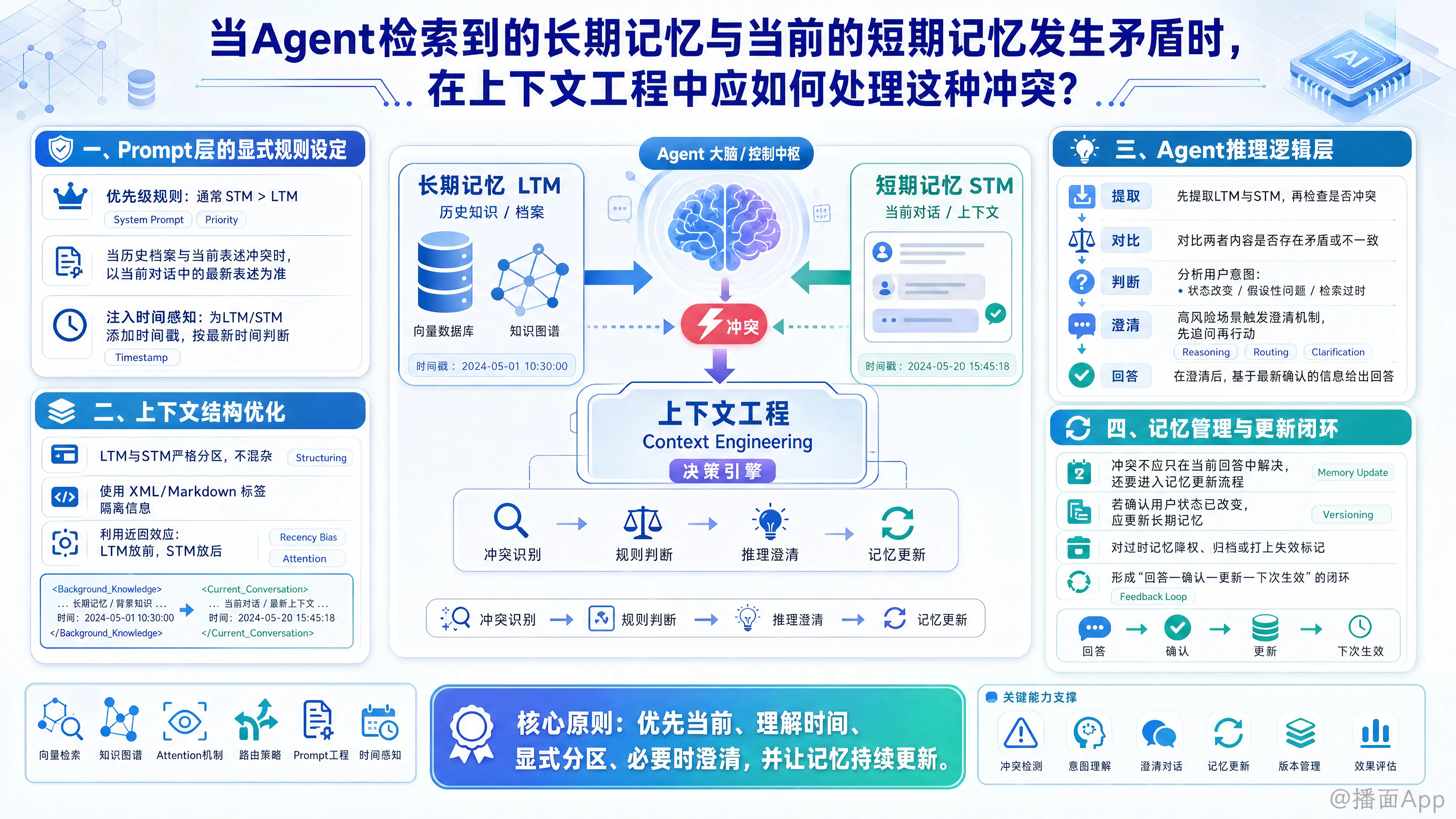
在Agent的架构中,长期记忆(Long-Term Memory, LTM,通常来自向量数据库或知识图谱的检索)与短期记忆(Short-Term Memory, STM,即当前的上下文对话窗口)发生冲突是一个非常经典的难题。
这通常意味着用户状态发生了改变、用户提出了假设性问题,或者检索到了过时的信息。
在上下文工程(Context Engineering)中,处理这种冲突需要从Prompt设计、上下文结构、Agent推理逻辑以及记忆更新机制四个维度来系统性地解决。以下是具体的处理策略:
一、 Prompt 层的显式规则设定 (Explicit Prompting)
最直接的方法是在系统提示词(System Prompt)中为大模型(LLM)设定明确的优先级规则和时间感知能力。
设定绝对的优先级(通常是 STM > LTM):
在Prompt中明确告诉Agent,当两者冲突时,以眼前的对话为准。Prompt 示例:
"你拥有用户的历史档案(LTM)和当前的对话记录(STM)。如果历史档案中的信息与当前用户的表述发生矛盾,请始终以当前对话(STM)中的最新表述为准,因为用户的偏好和状态可能已经发生改变。"注入时间戳(Time-Awareness):
冲突往往是因为时间错位。在组装上下文时,强制为LTM和STM打上时间标签。Prompt 示例:
"[历史记忆] 2023-05-12:用户表示讨厌喝咖啡。
[当前对话] 2023-10-24:用户说 '我最近开始每天早上喝美式了'。
规则:处理冲突时,请参考最新的时间戳。"
二、 上下文结构优化 (Context Structuring)
LLM 的注意力机制(Attention Mechanism)对输入文本的位置非常敏感。你可以通过排版和标签来引导模型处理冲突。
信息隔离(使用 XML/Markdown 标签):
不要把检索到的LTM和当前的STM混杂在一起,要严格分区,让模型清楚什么是“背景”,什么是“当下”。xml<Background_Knowledge> {这里放置检索到的LTM} </Background_Knowledge> <Current_Conversation> {这里放置STM对话历史} </Current_Conversation>利用“近因效应”(Recency Bias):
Transformer模型通常对靠近末尾(离生成任务最近)的Token分配更多的注意力。因此,在组装Prompt时,将 LTM 放在前面,将 STM 放在最后。
三、 Agent 推理逻辑层 (Reasoning & Routing)
让Agent不仅仅是“读取”上下文,而是主动“思考”和“对比”上下文。
要求模型进行“反思” (CoT - 思维链):
在生成最终回答前,强制模型先输出冲突分析。Prompt 示例:
"在回答用户前,请按以下步骤思考:- 提取 LTM 中的相关信息。
- 提取 STM 中的相关信息。
- 检查两者是否存在矛盾。
- 如果有矛盾,分析用户意图(是改变了想法、还是假设性提问?)。
- 给出最终回答。"
触发“澄清机制” (Human-in-the-loop / Clarification):
如果是高风险领域的冲突(如医疗过敏史、金融密码变更),Agent 不应自行盲目决定,而应向用户确认。处理逻辑: 识别到核心数据的冲突 -> 挂起当前任务 -> 发起追问:“我记得您之前对青霉素过敏,但您刚刚提到要使用它。请问您的过敏史是否有更新?”
四、 记忆管理与更新闭环 (Memory Update Mechanism)
冲突的发生,其实是触发长期记忆更新的最佳时机。上下文工程不仅是把文字喂给模型,还包括上下文的生命周期管理。
异步的“记忆修改者” Agent (Memory Updater):
当主Agent在回答时解决了冲突(例如确认用户现在喜欢咖啡了),后台应该有一个专门的子Agent或流程,去向量数据库/图谱中执行Update或Delete操作。机制: 识别到 STM 覆盖了 LTM -> 提取新事实 -> 覆写旧的 LTM 向量块,或在知识图谱中更新关系(如
User -[likes]-> Coffee)。时效性衰减 (Time-Weighted Retrieval):
在检索 LTM 组装上下文之前,在 RAG 阶段就过滤掉过时的记忆。评分公式可以设计为:最终得分 = 语义相似度得分 + 时间衰减权重。这样,越久远的冲突记忆,越不容易被检索进入当前的上下文中。
总结:最佳实践范式
在实际的Agent开发中,处理这两种记忆冲突的标准流水线应该是:
- 检索时:附带时间戳和置信度。
- 组装时:LTM在上,STM在下,用标签严格隔离。
- 提示时:加入“STM优先级最高”的System Prompt。
- 生成时:通过CoT让模型自行识别并解释变化。
- 结束时:后台触发记忆更新机制,修正长期记忆,避免下次对话再次冲突。