如何区分和实现Agent的“语义记忆(Semantic Memory)”和“情景记忆(Episodic Memory)”
在AI Agent的架构中,语义记忆(Semantic Memory)和情景记忆(Episodic Memory)是长期记忆(Long-term Memory)的两个核心基石。这两个概念借鉴自人类的认知心理学。
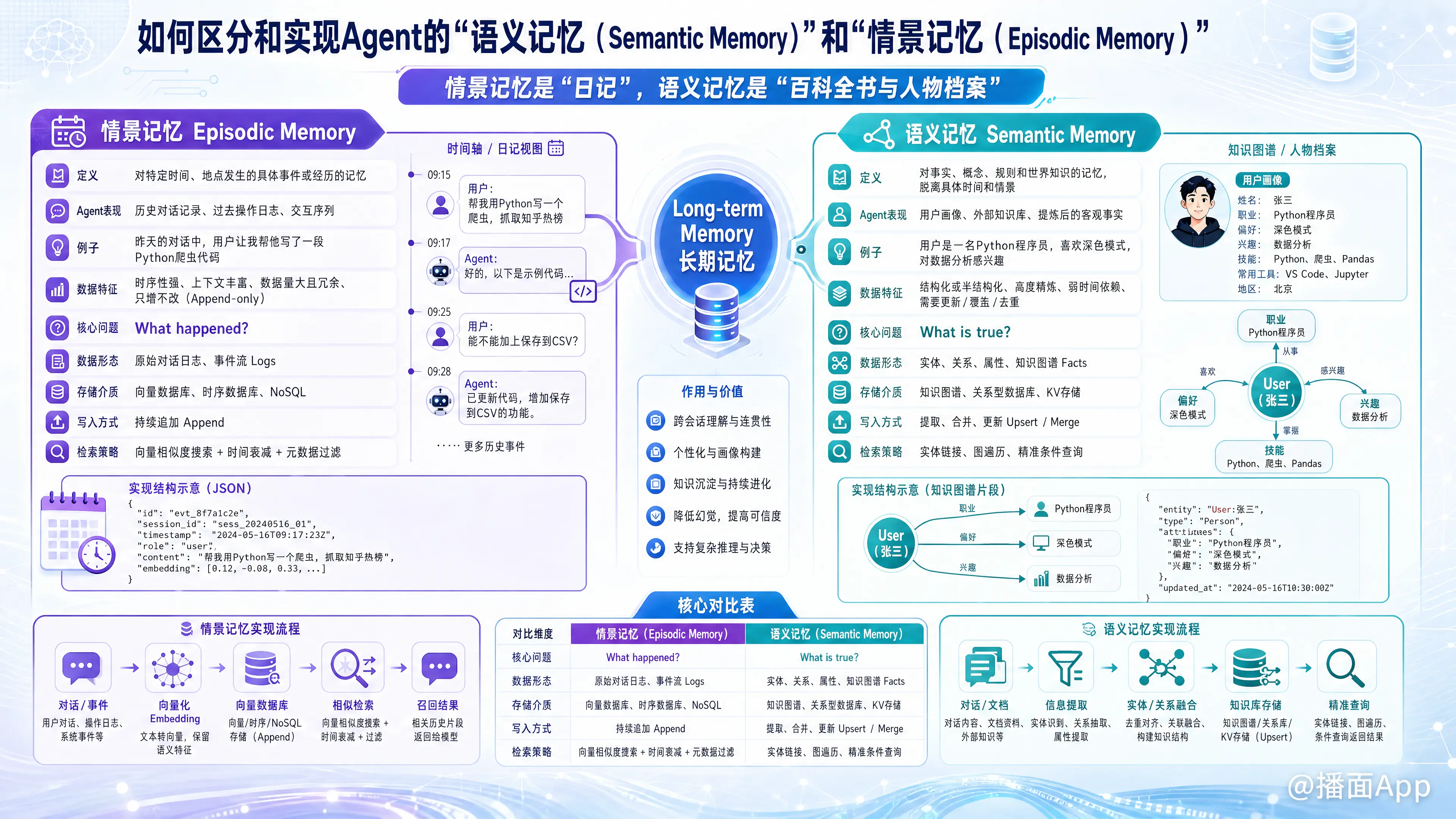
要构建一个既能“记住你说过什么”,又能“懂你这个人”的高级Agent,必须明确区分并分别实现这两种记忆。以下是详细的区分与实现指南。
一、 如何区分(概念与特征)
简单来说:情景记忆是“日记”,语义记忆是“百科全书与人物档案”。
1. 情景记忆 (Episodic Memory)
- 定义:对特定时间、地点发生的具体事件或经历的记忆。
- 在Agent中的表现:历史对话记录、过去的特定操作日志、交互序列。
- 人类例子:“我记得上周三你在咖啡馆帮我修好了电脑。”
- Agent例子:“昨天的对话中,用户让我帮他写了一段Python的爬虫代码。”
- 数据特征:时序性强、包含上下文(时间/地点/情绪)、数据量大且冗余、只增不改(Append-only)。
2. 语义记忆 (Semantic Memory)
- 定义:对事实、概念、规则和世界知识的记忆,脱离了具体发生的时间和情景。
- 在Agent中的表现:用户画像(偏好、职业)、外部知识库、经过提炼的客观事实。
- 人类例子:“我知道巴黎是法国的首都。”(你可能忘了是哪天学到的,但你知道这个事实)。
- Agent例子:“用户是一名Python程序员,喜欢深色模式,对数据分析感兴趣。”
- 数据特征:结构化或半结构化、高度精炼、无严格时间戳依赖、需要不断更新/覆盖/去重(Update & Deduplicate)。
3. 核心对比表
| 维度 | 情景记忆 (Episodic) | 语义记忆 (Semantic) |
|---|---|---|
| 核心问题 | What happened? (发生了什么) | What is true? (什么是事实) |
| 数据形态 | 原始对话日志、事件流 (Logs) | 实体、关系、属性、知识图谱 (Facts) |
| 存储介质 | 向量数据库、时序数据库、NoSQL | 知识图谱 (Graph DB)、关系型数据库、KV存储 |
| 写入方式 | 持续追加 (Append) | 提取、合并、更新 (Upsert / Merge) |
| 检索策略 | 向量相似度搜索 + 时间衰减过滤 | 实体链接、图遍历、精准条件查询 |
二、 如何实现情景记忆 (Episodic Memory)
情景记忆的实现相对直接,主流方案是向量数据库 + 带有元数据的文本块。
1. 数据结构设计
每条记忆需要包含原始文本和丰富的上下文元数据(Metadata):
json
{
"id": "msg_001",
"session_id": "session_998",
"timestamp": "2023-10-25T14:30:00Z",
"role": "user",
"content": "帮我定一张明天去北京的高铁票",
"embedding": "[0.012, -0.045, ...]" // 向量化表示
}2. 存储与检索策略
- 存储:使用 Chroma, Pinecone, Milvus 等向量数据库。
- 检索(Retrieval):
- Top-K 相似度检索:当用户问“我昨天让你定的票怎么样了”,Agent将此查询向量化,寻找最相关的历史对话。
- 时间衰减(Time Decay):在计算相似度得分时,加入时间惩罚因子。越久远的对话,权重越低。
- 元数据过滤(Metadata Filtering):结合时间范围过滤(如
timestamp > '2023-10-24')。
3. 实现伪代码(Python + LangChain 概念)
python
from vector_db import VectorStore
from embedding_model import get_embedding
class EpisodicMemory:
def __init__(self):
self.db = VectorStore()
def add_memory(self, session_id, role, text):
vector = get_embedding(text)
metadata = {
"session_id": session_id,
"timestamp": get_current_time(),
"role": role
}
self.db.insert(vector=vector, text=text, metadata=metadata)
def retrieve(self, query, top_k=5):
query_vector = get_embedding(query)
# 向量相似度搜索 + 时间衰减排序
results = self.db.search(query_vector, top_k=top_k, apply_time_decay=True)
return results三、 如何实现语义记忆 (Semantic Memory)
语义记忆的实现更加复杂,因为它需要信息抽取和冲突解决。主流方案是知识图谱(Knowledge Graph)或结构化的用户画像数据库。
1. 数据结构设计
通常以“三元组(实体-关系-实体)”或“Key-Value实体属性”形式存在:
- 用户画像 (User Profile):
{"user_name": "Alice", "profession": "Engineer", "diet": "Vegan"} - 知识图谱 (Graph):
(Alice) -[LIVES_IN]-> (Beijing)
2. 更新机制 (Memory Consolidation)
语义记忆不能直接追加,必须通过 LLM 进行提取和整合。
- 触发时机:可以在每轮对话后异步执行,或者当情景记忆积累到一定量时批量执行。
- 提取 (Extraction):让 LLM 从对话中提取事实(如:“用户刚说他搬到了上海”)。
- 合并/冲突解决 (Conflict Resolution):如果之前的记忆是
(Alice)-[LIVES_IN]->(Beijing),Agent需要使用LLM判断并更新为(Alice)-[LIVES_IN]->(Shanghai)。
3. 存储与检索策略
- 存储:Neo4j (图数据库), PostgreSQL (结构化属性), 或带有特定命名空间的向量数据库 (结合 GraphRAG)。
- 检索:
- 实体识别(NER):从当前用户查询中识别出实体(如“上海”)。
- 图查询/SQL:直接查询该实体的相关属性。
4. 实现伪代码
python
class SemanticMemory:
def __init__(self):
self.knowledge_graph = GraphDatabase()
self.llm = LLM()
def update_memory(self, latest_dialogue):
# 1. 使用LLM从对话中提取事实
prompt = f"从以下对话中提取关于用户的永久性事实,格式为JSON:{latest_dialogue}"
new_facts = self.llm.generate(prompt) # e.g., {"location": "Shanghai"}
# 2. 解决冲突并更新知识库 (Upsert)
for fact_key, fact_value in new_facts.items():
self.knowledge_graph.upsert_user_property(fact_key, fact_value)
def retrieve(self, query):
# 提取query中的实体并查询图谱
entities = self.llm.extract_entities(query)
facts = self.knowledge_graph.get_subgraph(entities)
return facts四、 架构整合:两种记忆如何协同工作?
在顶级的 AI Agent 架构(如 MemGPT 或 斯坦福的 Generative Agents)中,这两种记忆是协同运作的。
典型的工作流(Workflow):
- 用户输入:“我下周要去滑雪,我该带什么?”
- 记忆检索阶段:
- 检索语义记忆:Agent发现“用户居住在南方”、“用户是初学者”、“用户怕冷”(精准事实)。
- 检索情景记忆:Agent发现“上个月用户提到买了一件蓝色的防风夹克”(具体事件)。
- Prompt 组装:
将检索到的语义信息和情景信息放入 System Prompt。 - LLM 生成回复:
“考虑到你是滑雪初学者而且比较怕冷(语义),建议你多带几件保暖内衣。对了,你可以带上你上个月买的那件蓝色防风夹克(情景),它很适合滑雪。” - 记忆巩固阶段(后台异步):
将这次对话存入情景记忆(追加日志)。同时,启动后台线程,让 LLM 总结这次对话,提取出“用户下周去滑雪”存入语义记忆(更新状态)。
总结建议
- 如果是 MVP(最小可行性产品):先只做基于向量数据库的情景记忆,通过滑动窗口+向量检索即可满足 80% 的日常对话需求。
- 如果要做高级个性化助手(如个人AI伴侣、专属导师):必须引入语义记忆。建议引入 GraphRAG 技术或专门的用户画像系统,让 Agent 具备真正的“心智模型(Theory of Mind)”,能够记住并理解用户的本质特征,而不是仅仅复读过去的对话。
右滑查看面试常问