在构建Agent上下文时应如何规避处理中的“迷失在中间(Lost in the Middle)”效应?
大模型(LLM)在长上下文处理中的“迷失在中间(Lost in the Middle, 简称 LitM)”效应,是当前AI应用开发(尤其是RAG和Agent开发)中必须面对的一个经典难题。
下面我将详细解释这一效应的原理,并给出在组装Agent上下文时规避该问题的一整套实用策略。
一、 什么是“迷失在中间”效应?
定义:
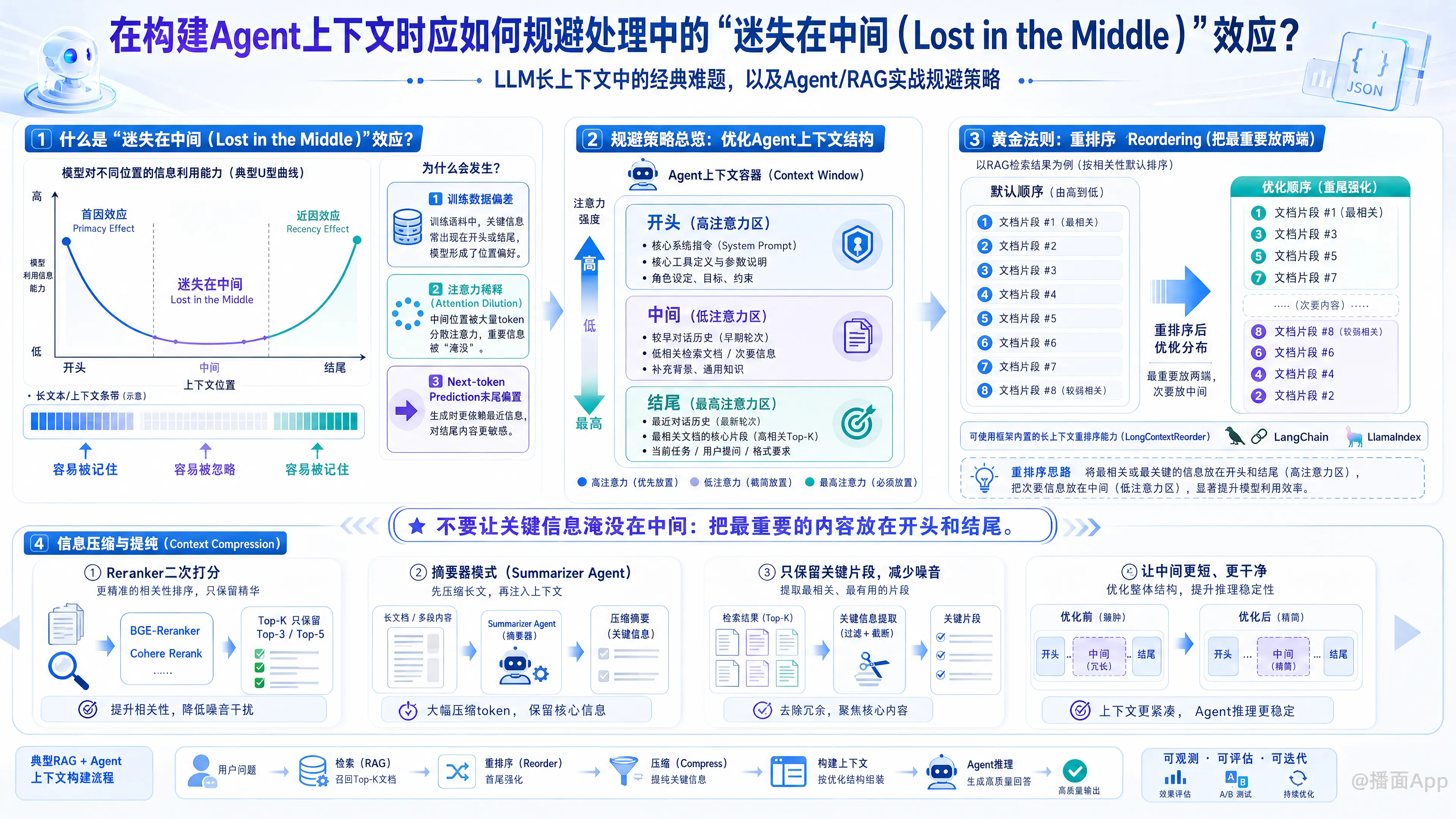
斯坦福大学等机构的研究人员发现,当给大模型输入一段非常长的文本(例如包含几十个检索文档或超长对话历史)时,大模型在提取和利用信息时呈现出一种“U型”性能曲线:
- 首因效应(Primacy Effect):模型非常擅长提取位于提示词最开头的信息。
- 近因效应(Recency Effect):模型也非常擅长提取位于提示词最末尾(即最靠近提问处)的信息。
- 迷失在中间(Lost in the Middle):对于隐藏在长文本中间部分的关键信息,模型的检索和推理准确率会断崖式下降,常常发生忽略、幻觉或回答“我不知道”。
为什么会产生这种现象?
- 训练数据偏差:人类写作的文章(如新闻、论文)通常把最核心的信息放在开头(摘要/导语)或结尾(总结)。模型在海量人类文本上训练,潜移默化地学到了“开头和结尾更重要”的启发式规则。
- 注意力稀释(Attention Dilution):Transformer架构的自注意力机制在面对几万个Token时,注意力权重会被过度分散。
- 下一个词预测(Next-token Prediction)特质:语言模型的生成最直接依赖于它刚刚看到的几个词(即上下文的末尾),因此末尾信息的权重天然最高。
二、 在组装 Agent 上下文时如何规避该问题?
AI Agent 通常需要加载非常复杂的上下文(系统指令、工具描述、对话历史、检索到的外部文档、当前任务等)。为了防止 Agent 在执行任务时“忽略中间的工具描述”或“漏掉中间的检索结果”,可以采取以下策略:
1. 黄金法则:重排序(Reordering)
既然模型对开头和结尾最敏感,我们就应该把最重要的数据放在两端,最不重要的数据放在中间。
- 文档重排序(Document Reordering):
在RAG(检索增强生成)中,默认的向量检索结果是按相关性从高到低排列(1, 2, 3, 4, 5)。
正确做法是将其交替排列,把最相关的放在首尾,相关性差的塞在中间。
排序顺序变为:[1, 3, 5, 7, ..., 8, 6, 4, 2]。LangChain 和 LlamaIndex 中都内置了LongContextReorder功能来实现这一点。 - Agent 整体上下文布局:
一个抗 LitM 效应的 Agent Prompt 最佳结构如下:[开头 - 高注意力区]
- 核心系统指令(Agent 角色、最高准则)
- 核心工具的定义和参数说明
[中间 - 低注意力区]
3. 较早的对话历史
4. 相关度较低的检索文档 / 补充背景[结尾 - 最高注意力区]
5. 最近的对话回合(Short-term memory)
6. 最相关的检索文档核心片段
7. 当前的具体任务 / 用户提问 / 强制格式要求(如“请输出JSON”)
2. 信息压缩与提纯(Context Compression)
不要试图把所有东西都塞进上下文,消除中间的“噪音”是根本的解决之道。
- 使用 Reranker(重排模型):在将检索到的数十个文档喂给 Agent 之前,先用 BGE-Reranker 或 Cohere Rerank 这种交叉编码器进行二次打分,剔除无关文档,只保留 Top-3 或 Top-5。
- 摘要器模式(Summarizer Agent):如果必须阅读长文档,先让一个小模型(或开销较小的子 Agent)对长文档进行“关键信息抽取”或“摘要”,把 10000 字浓缩为 1000 字的要点,再喂给主 Agent。
- 精简工具描述:如果 Agent 有 20 个工具,不要把所有工具的详细说明都放在 Prompt 里。可以使用动态工具检索(根据用户的意图,只把最可能用到的 3-5 个工具的描述加载到上下文中)。
3. 强化提示词工程(Prompt Engineering Tips)
通过特定格式和指令,强迫模型将注意力集中在特定的区域:
- 结构化标记(XML / Markdown):使用明确的界限符号。大模型对 XML 标签很敏感。xml
<tools> 工具列表... </tools> <history> 历史... </history> <documents> 检索文档... </documents> - 结尾处进行“注意力强提醒”:在 Prompt 的最后一句,再次重复关键约束。
错误:(把约束写在开头) “你必须只使用上述文档回答,并调用 calculator 工具。” -> (中间隔了2万字) -> “用户提问:苹果利润多少?”
正确:(在结尾处补充) “用户提问:苹果利润多少?请务必仔细阅读<documents>标签中的所有内容(即使是中间部分),并使用 calculator 工具计算。” - 强制思维链(Chain of Thought, CoT)提取:
要求模型在给出最终答案前,先把所有支撑材料“抄写”一遍。
例如加入指令:“在回答前,请先使用<scratchpad>标签,从上文提取出与问题相关的原句,并注明出处,然后再综合出你的答案。” 这会强制模型的注意力扫过整个文本。
4. Agent 架构的优化(分而治之)
将一个具有庞大上下文的“全能巨型 Agent”拆分成多个专注的“多智能体(Multi-Agent)”协同系统。
- 路由-执行模式:Router Agent (只看用户提问和工具列表) -> 分发给具体的 Tool Agent (只加载与该工具相关的几百字背景)。
- 阅读理解模式:不要让主执行 Agent 一次性看 50 页报告,而是让它调用
Read_Document_Chunk(page=5)工具,一页一页地翻看并做笔记。
5. 选择具备抗 LitM 能力的模型
虽然几乎所有模型都有不同程度的 LitM 效应,但最新的大模型通过扩展 RoPE(旋转位置编码)、Ring Attention 或 YARN 等技术,在这方面有了巨大进步。
如果你的 Agent 必须处理长上下文,请优先选择:
- Claude 3.5 Sonnet / Opus (目前在长上下文“大海捞针”测试中表现最好之一)
- Gemini 1.5 Pro (原生支持百万 Token,LitM 效应相对较弱)
- GPT-4o (在 128k 上下文内性能较稳定)
总结:
在开发 Agent 时,不要迷信模型宣称的“支持 128k 甚至 1M 上下文”。把上下文当成极其昂贵的注意力资源来管理。遵循“少即是多(精简提纯)”和“两头最重(重排序)”的原则,是规避“迷失在中间”效应的最有效手段。