std::vector 和 std::list 的底层数据结构、优缺点及适用场景
在C++ STL(标准模板库)中,std::vector 和 std::list 是最常用的两种顺序容器。它们在底层设计上有着本质的区别,这也决定了它们在不同场景下的表现。
以下是它们的底层数据结构、优缺点及适用场景的详细对比:
一、 std::vector (动态数组)
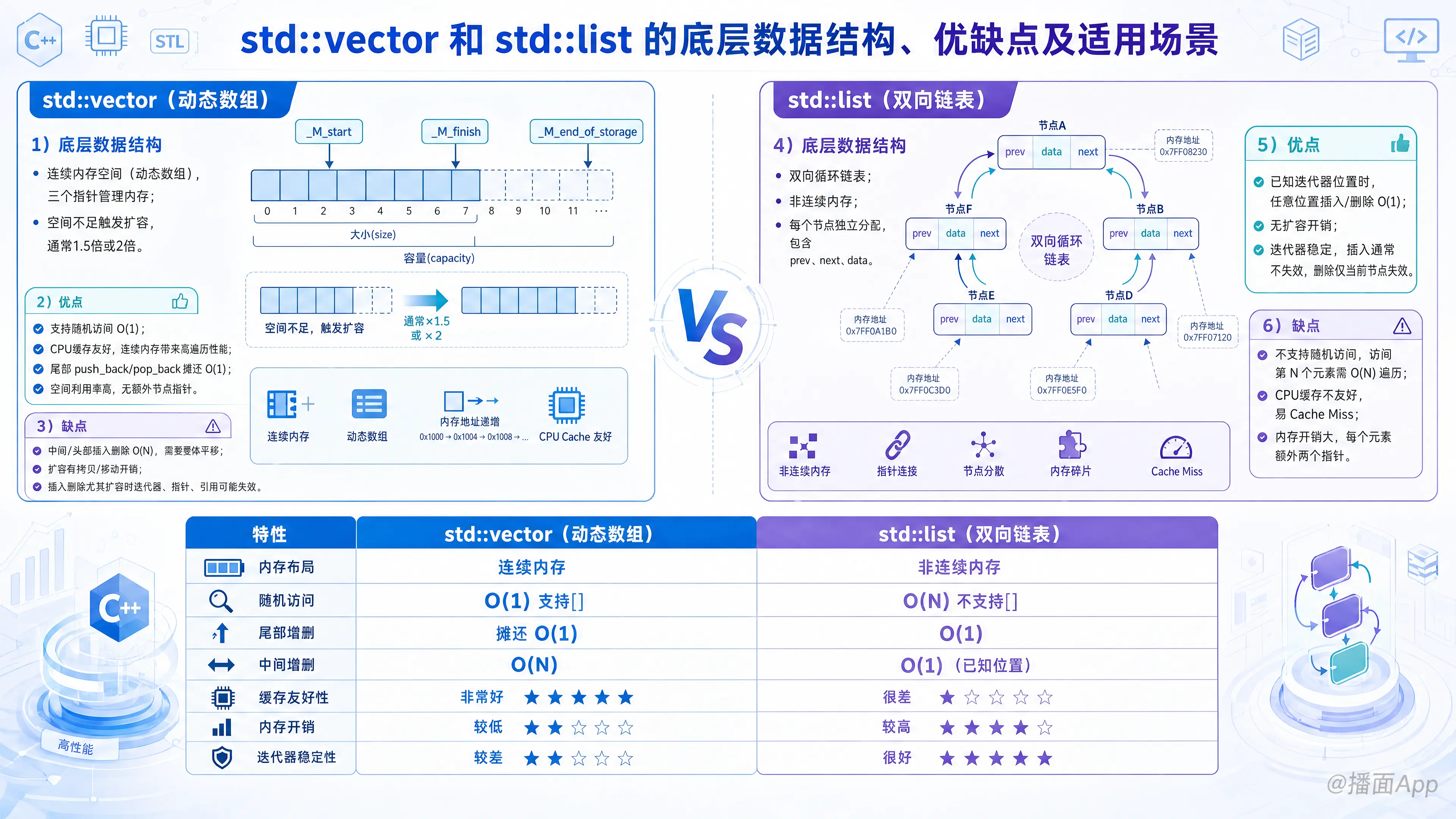
1. 底层数据结构
std::vector 的底层是一段连续的内存空间(动态数组)。
它通常包含三个指针来管理内存:
_M_start:指向已分配空间的起始位置。_M_finish:指向已存储元素的末尾位置。_M_end_of_storage:指向已分配内存空间的末尾。
当空间不足时(size == capacity),它会触发扩容机制:申请一块更大的新连续内存(通常是原容量的1.5倍或2倍,取决于编译器实现),将旧数据拷贝/移动到新内存中,然后释放旧内存。
2. 优点
- 支持随机访问:由于内存连续,可以通过索引
$O(1)$时间复杂度直接访问任何元素(如vec[5])。 - CPU 缓存友好(Cache-friendly):这是
vector最大的隐藏优势。连续的内存使得 CPU 预取机制能极大地提高数据读取速度(空间局部性极佳)。 - 尾部操作极快:在尾部插入和删除元素(
push_back/pop_back)的时间复杂度为摊还 。 - 空间利用率高:相比于链表,它不需要为每个元素存储额外的指针,内存开销较小。
3. 缺点
- 中间或头部插入/删除极慢:需要将插入点之后的所有元素进行整体平移,时间复杂度为
$O(N)$。 - 扩容开销大:一旦触发动态扩容,涉及大量数据的拷贝或移动操作。
- 迭代器失效:插入和删除操作(特别是触发扩容时)会导致指向容器内元素的指针、引用和迭代器全部失效。
二、 std::list (双向链表)
4. 底层数据结构
std::list 的底层是一个双向循环链表。
它的内存空间是非连续的。每个元素都被包装在一个独立的“节点(Node)”中,节点在堆上单独分配。每个节点包含三部分:
prev:指向前一个节点的指针。next:指向后一个节点的指针。data:实际存储的数据。
5. 优点
- 任意位置插入/删除极快:只要你拥有指向某位置的迭代器,在该位置进行插入或删除操作的时间复杂度严格为
$O(1)$,只需要修改几个指针的指向即可。 - 无扩容开销:每次新增元素都是单独分配一块小内存,永远不需要像
vector那样大规模拷贝数据。 - 迭代器极少失效:插入操作不会导致任何迭代器失效;删除操作只会导致被删除元素的迭代器失效,其他元素的迭代器、指针和引用仍然完全有效。
6. 缺点
- 不支持随机访问:想要访问第 个元素,必须从头或尾开始遍历指针,时间复杂度为
$O(N)$。不能使用list[5]这种语法。 - CPU 缓存极度不友好:由于内存是不连续的“碎片化”分布,CPU 访问时会频发 Cache Miss(缓存未命中),导致实际遍历速度远慢于
vector。 - 内存开销大:每个元素都需要额外存储两个指针(在 64 位系统上额外增加 16 字节),对于小数据类型(如
int或char),内存浪费非常严重。
三、 核心对比总结表
| 特性 | std::vector (动态数组) |
std::list (双向链表) |
|---|---|---|
| 内存布局 | 连续内存 | 非连续内存(节点分散) |
| 随机访问 | $O(1)$ (支持 [] 操作符) |
$O(N)$ (不支持 [] 操作符) |
| 尾部增删 | 摊还 $O(1)$ |
$O(1)$ |
| 中间/头部增删 | $O(N)$ (需要移动元素) |
$O(1)$ (仅限已知迭代器位置) |
| 空间开销 | 小(仅预留 capacity 空间) | 大(每个节点多2个指针开销) |
| CPU 缓存亲和度 | 极高(顺序遍历极快) | 极低(容易引发 Cache Miss) |
| 迭代器失效情况 | 扩容全失效;增删点后的全失效 | 仅被删除的节点失效 |
四、 适用场景 (如何选择?)
默认选择:优先使用 std::vector
C++ 之父 Bjarne Stroustrup 曾强烈建议:在没有明确理由的情况下,默认使用 std::vector。
即使你需要在中间插入数据,对于少量数据或小体积数据,vector 因为 CPU 缓存的优势,其整体性能通常仍碾压 list。
适用 std::vector 的场景:
- 高频随机访问:需要频繁通过索引获取数据(如
v[i])。 - 数据量已知或变化不大:可以通过
reserve()提前分配内存,彻底消除扩容开销。 - 主要在尾部追加数据:如日志记录、收集数据的缓冲池。
- 对性能要求苛刻且需频繁遍历:
vector的连续内存能最大化利用 CPU L1/L2 缓存。
适用 std::list 的场景:
- 极度频繁在中间进行插入和删除:例如实现 LRU 缓存淘汰算法,或者某些文本编辑器底层的数据结构。
- 元素体积非常庞大:如果存储的类非常大(且未实现高效的移动语义),
vector移动元素的代价会远高于list改变指针的代价。 - 必须保证迭代器/指针的稳定性:你的业务逻辑强依赖于元素的绝对物理地址,即使容器增删元素,外部保留的指向该元素的指针也不能失效。
(注:如果你只需要单向链表,且极度渴求节省内存,可以考虑 C++11 引入的 std::forward_list,它比 std::list 更轻量。)
右滑查看面试常问