C++中的左值 (Lvalue) 和右值 (Rvalue)
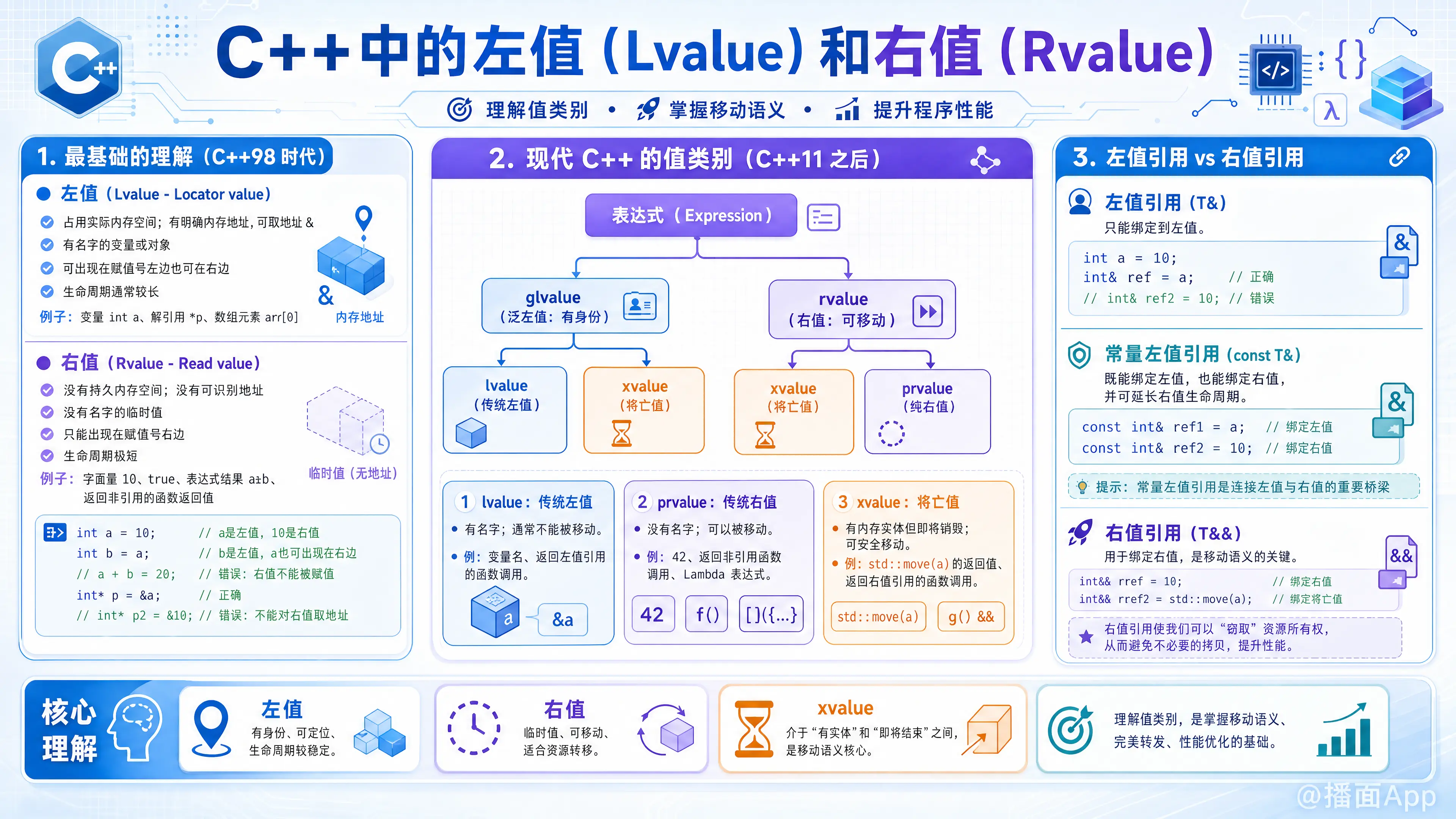
在 C++ 中,左值(Lvalue)和右值(Rvalue)是理解 C++ 核心机制(尤其是 C++11 引入的移动语义和完美转发)的基础。
简单来说,这两个概念定义了表达式的“身份”和“生命周期”。
1. 最基础的理解(C++98 时代)
在早期的 C++ 或 C 语言中,分类非常直观:
- 左值 (Lvalue - Locator value):
- 定义: 占用实际的内存空间、有明确的内存地址(可以取地址
&)、有名字的变量或对象。 - 特征: 它可以出现在赋值号
=的左边,也可以在右边。它的生命周期通常较长(直到离开作用域)。 - 例子: 变量
int a、解引用*p、数组元素arr[0]。
- 定义: 占用实际的内存空间、有明确的内存地址(可以取地址
- 右值 (Rvalue - Read value):
- 定义: 不占用持久的内存空间、没有可识别的内存地址、没有名字的临时值。
- 特征: 它只能出现在赋值号
=的右边。它的生命周期极短(通常在当前语句执行完后销毁)。 - 例子: 字面量
10、true、表达式计算结果a + b、返回非引用的函数返回值。
代码示例:
int a = 10; // 'a' 是左值(有地址,能被赋值),'10' 是右值(临时字面量)
int b = a; // 'b' 是左值,'a' 作为左值出现在右边也可以
a + b = 20; // 错误!'a + b' 产生一个临时结果,是右值,不能被赋值
int* p = &a; // 正确!可以对左值取地址
int* p2 = &10; // 错误!不能对右值取地址2. 现代 C++ 的值类别(C++11 之后)
随着 C++11 引入了右值引用(Rvalue reference, &&)和移动语义(Move semantics),左值和右值的分类变得更加精细。
现代 C++ 将表达式分为三大基础类别(和两个复合类别),可以用以下树状图表示:
表达式 (Expression)
├── glvalue (泛左值: Generalized lvalue) - 有身份(有内存地址)
│ ├── lvalue (传统左值)
│ └── xvalue (将亡值: Expiring value)
│
└── rvalue (右值) - 可移动(允许被安全地“偷”走资源)
├── xvalue (将亡值: Expiring value)
└── prvalue (纯右值: Pure rvalue)核心三类别:
- lvalue(左值): 传统的左值。有名字,不能被移动(Move)。
- 例:变量名、返回左值引用的函数调用(如
std::cout)。
- 例:变量名、返回左值引用的函数调用(如
- prvalue(纯右值): 传统的右值。没有名字,可以被移动。
- 例:字面量(
42)、返回非引用的函数调用(int foo())、Lambda 表达式。
- 例:字面量(
- xvalue(将亡值): C++11 新增。它既有名字(有内存实体),又马上要被销毁(可以被移动)。
- 例:
std::move(a)的返回值、返回右值引用的函数调用。
- 例:
3. 左值引用 vs 右值引用
为了操作这些不同类型的值,C++ 提供了不同类型的引用:
① 左值引用 (T&)
只能绑定到左值上。
int a = 10;
int& ref = a; // 正确
int& ref2 = 10; // 错误!不能用非 const 左值引用绑定右值② 常量左值引用 (const T&)
万能引用(早期)。它既能绑定左值,也能绑定右值(此时会延长右值的生命周期)。
int a = 10;
const int& ref = a; // 正确,绑定左值
const int& ref2 = 10; // 正确,绑定右值!'10' 的生命周期被延长到和 ref2 一样注:这也是为什么 C++98 中很多函数的参数写成 const std::string&,因为它既能接收变量,也能接收 "hello" 这样的临时字符串。
③ 右值引用 (T&&) —— C++11 新增
只能绑定到右值上(prvalue 或 xvalue)。 它的出现是为了实现“移动语义”。
int&& rref = 10; // 正确,绑定纯右值
int a = 20;
int&& rref2 = a; // 错误!右值引用不能绑定到左值上
int&& rref3 = std::move(a); // 正确!std::move 强制将左值转换为右值(将亡值 xvalue)4. 为什么要区分左值和右值?(极度重要)
引入右值和右值引用的核心目的在于性能优化(消除不必要的拷贝)。
假设你有一个包含大量数据的类 MyString:
MyString createString() {
MyString temp("Hello World, this is a very long string");
return temp;
}
MyString str = createString(); 在 C++11 之前(只有左值引用):
createString()内部创建一个temp。- 返回时,产生一个临时对象(右值)。把
temp拷贝给这个临时对象(深拷贝,极度耗时)。 - 把临时对象拷贝给
str(再次深拷贝)。 - 销毁
temp和临时对象。
结果:为了把数据给str,我们开辟了多次内存并复制了多遍。
在 C++11 之后(有了右值引用和移动语义):
编译器知道 createString() 返回的是一个临时对象(右值),马上就要被销毁了。
因此,C++ 不会执行深拷贝,而是调用 移动构造函数(Move Constructor)。
移动构造函数做的事情是:直接“偷”走临时对象内部的指针,把临时对象的指针置为空。
结果:O(1) 的时间复杂度,没有内存分配,没有数据拷贝。
5. std::move 是什么?
std::move 的名字非常有欺骗性,它实际上不移动任何东西!
它本质上只是一个类型转换。它将一个左值强制转换为右值引用(xvalue),从而告诉编译器:“我不再需要这个左值了,你可以像对待右值一样,把它的资源偷走(移动)”。
std::string s1 = "Hello";
std::string s2 = std::move(s1); // s1 被转换为右值,触发了 s2 的移动构造函数
// 此时 s1 的内容已经被“偷”走了,通常变为空字符串 ""6. 一个极其常见的陷阱(重点提醒)
右值引用类型的变量,本身是一个左值!
void process(int&& rval) {
// 这里的 rval 虽然类型是“右值引用”
// 但因为 rval 有名字,而且你可以取它的地址 (&rval)
// 所以在 process 函数内部,rval 是一个 左值!
int a = rval; // OK
int&& b = rval; // 错误!不能把左值赋给右值引用
int&& c = std::move(rval); // 正确,必须再次转换
}总结
- 左值:有名字、能取地址、持久的变量。
- 右值:没名字、不能取地址、转瞬即逝的临时值(或通过
std::move强转的值)。 - 左值引用 (
&):传统的引用,别名。 - 右值引用 (
&&):C++11 引入,专门用来绑定临时对象,用于“榨干/偷走”临时对象的资源,避免深拷贝,大幅提升程序性能。