Sleuth 的底层原理是什么?
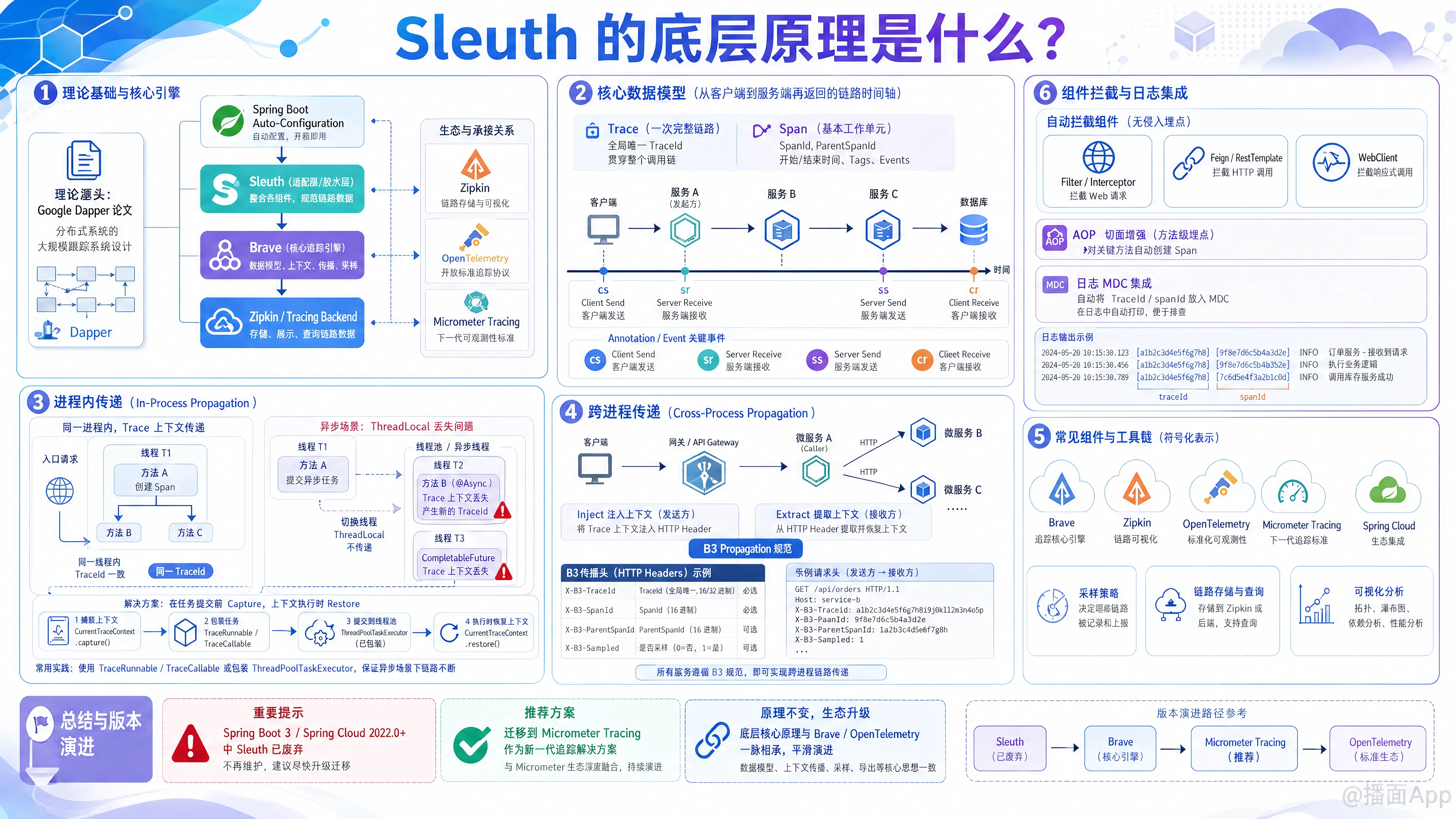
Spring Cloud Sleuth 是 Spring Cloud 生态中用于实现分布式链路追踪的核心组件。要理解它的底层原理,我们需要从它的理论基础、核心数据模型、上下文传递机制、组件拦截(AOP/Filter)以及日志集成几个维度来剖析。
⚠️ 重要背景提示:在 Spring Boot 3.0 / Spring Cloud 2022.0 及更高版本中,Spring Cloud Sleuth 已经被废弃,其功能被迁移到了 Micrometer Tracing 中。但两者的核心底层理论(特别是基于 Brave 和 OpenTelemetry 的机制)是一脉相承的。
以下是 Sleuth 的底层原理深度解析:
1. 理论基础与核心引擎
Sleuth 的设计思想完全借鉴了 Google 的 Dapper 论文。
Sleuth 并不是从零开始写了一套追踪系统,它本质上是一个适配器(胶水层)。它的底层追踪引擎其实是 Brave(Zipkin 的 Java 客户端库)。Sleuth 的主要工作是将 Brave 无缝集成到 Spring Boot 的自动配置(Auto-configuration)中。
2. 核心数据模型
Sleuth 维护了三个核心概念(与 Dapper 论文一致):
- Trace(轨迹):一次完整的分布式请求链路。由一个全局唯一的
TraceId标识。 - Span(跨度):链路中的一个基本工作单元(例如一次 HTTP 请求、一次数据库调用)。包含
SpanId、ParentSpanId(父跨度ID)、开始时间、结束时间、标签(Tags)和事件(Events)。 - Annotation(注解/事件):用于记录特定事件的时间点,核心的四个事件是:
cs(Client Sent):客户端发送请求(Span 开始)。sr(Server Received):服务端接收请求。ss(Server Sent):服务端处理完成,准备回发响应。cr(Client Received):客户端接收到响应(Span 结束)。
3. 底层运行机制:上下文的流转
Sleuth 的核心任务是保证 TraceId 和 SpanId 能够在整个调用链路中不丢失。这分为“进程内传递”和“跨进程传递”。
A. 进程内传递 (In-Process Propagation)
在一个微服务内部,如何保证方法 A 调用方法 B 时,TraceId 是一致的?
- 原理:利用
ThreadLocal。Sleuth(底层是 Brave 的CurrentTraceContext)会将当前的 Trace/Span 信息绑定到当前线程的ThreadLocal中。 - 异步线程问题:如果使用了
@Async、自定义线程池或CompletableFuture,ThreadLocal会丢失。 - Sleuth 的解决办法:Sleuth 提供了自动配置,会包装 Spring 的
ThreadPoolTaskExecutor,或者提供TraceRunnable/TraceCallable。在任务提交给新线程前,提取当前线程的上下文并存入闭包;当任务在新线程运行时,再将上下文恢复到新线程的ThreadLocal中。
B. 跨进程传递 (Cross-Process Propagation)
微服务 A 通过 HTTP 或 RPC 调用微服务 B 时,如何传递 TraceId?
- 原理:协议头注入(Inject)与提取(Extract)。
- HTTP 场景:Sleuth 默认遵循 B3 传播规范 (B3 Propagation)。当发起请求时,它会在 HTTP 请求头(Headers)中注入以下字段:
X-B3-TraceId: 全局链路 IDX-B3-SpanId: 当前跨度 IDX-B3-ParentSpanId: 父跨度 IDX-B3-Sampled: 是否采样(是否将此数据发送到 Zipkin)
- MQ/消息队列场景:在发送 Kafka 或 RabbitMQ 消息时,Sleuth 会拦截消息,将 B3 信息注入到消息的 Header/Properties 中,消费者收到消息后再提取出来。
4. 无侵入拦截机制 (Instrumentation)
Sleuth 为什么能在不修改业务代码的情况下实现追踪?因为它利用 Spring 的扩展点实现了各种组件的拦截:
- Web MVC (接收 HTTP 请求):
Sleuth 注册了一个全局的Filter(通常是TracingFilter)。当请求到达时,Filter 检查 Request Header 中是否有 B3 相关的参数。如果有,则提取出来构建 Span;如果没有,则生成一个新的 TraceId 作为链路起点。最后存入ThreadLocal。 - RestTemplate / WebClient (发送 HTTP 请求):
Sleuth 自动注入了ClientHttpRequestInterceptor或ExchangeFilterFunction。在发起网络请求前,从ThreadLocal拿出 Span 信息,转换成 B3 Headers 塞进即将发出的 HTTP 请求中。 - Feign Client:
Sleuth 实现了 Feign 的RequestInterceptor,或者直接包装了 Feign 的Client组件,在发送前完成 Headers 的注入。 - 数据库/Redis:
通过集成外部库(如 P6Spy)或者 Spring Data 的拦截器,记录 SQL 或命令的执行时间并生成内部 Span。
5. 日志 MDC 集成 (Logging Integration)
为什么引入 Sleuth 后,我们的 Logback/Log4j 控制台日志会自动带上 [Service-Name, TraceId, SpanId]?
- 原理:Sleuth 集成了 SLF4J 的 MDC (Mapped Diagnostic Context,映射诊断上下文)。
- MDC 本质上也是基于
ThreadLocal的。当 Sleuth 创建或切换 Span 时,它会同步把traceId和spanIdput到 MDC 里面。 - 日志框架(如 Logback)在格式化输出时(
%X{traceId}),就能从 MDC 中读取到这些值打印出来。
6. 采样与数据上报 (Sampling & Exporting)
高并发下,如果每个请求都记录并发送追踪数据,会严重影响性能并占用极大带宽。
- 采样率 (Sampler):Sleuth 内部有
Sampler接口,默认是ProbabilityBasedSampler(例如配置spring.sleuth.sampler.probability=0.1表示只抓取 10% 的请求)。一旦决定采样,X-B3-Sampled就会被标记为 1,下游服务看到 1 也会强制采样。 - 异步上报:当一个 Span 结束时(例如 HTTP 响应返回),Sleuth/Brave 不会同步阻塞地把数据发给 Zipkin 等后端。而是将 Span 放入一个内存阻塞队列中,由后台独立的 Sender 线程通过 HTTP 或 Kafka/RabbitMQ 异步、批量地推送到 Zipkin Server。
总结
Sleuth 的底层可以用一句话概括:
以 Brave 为追踪引擎,利用 ThreadLocal 实现进程内上下文传递,利用 B3 规范和拦截器(AOP/Filter)实现跨进程的 HTTP/MQ Header 传递,通过 MDC 实现日志关联,最后通过异步线程池将采样后的链路数据上报给监控服务端。