PriorityQueue(优先队列)的底层原理
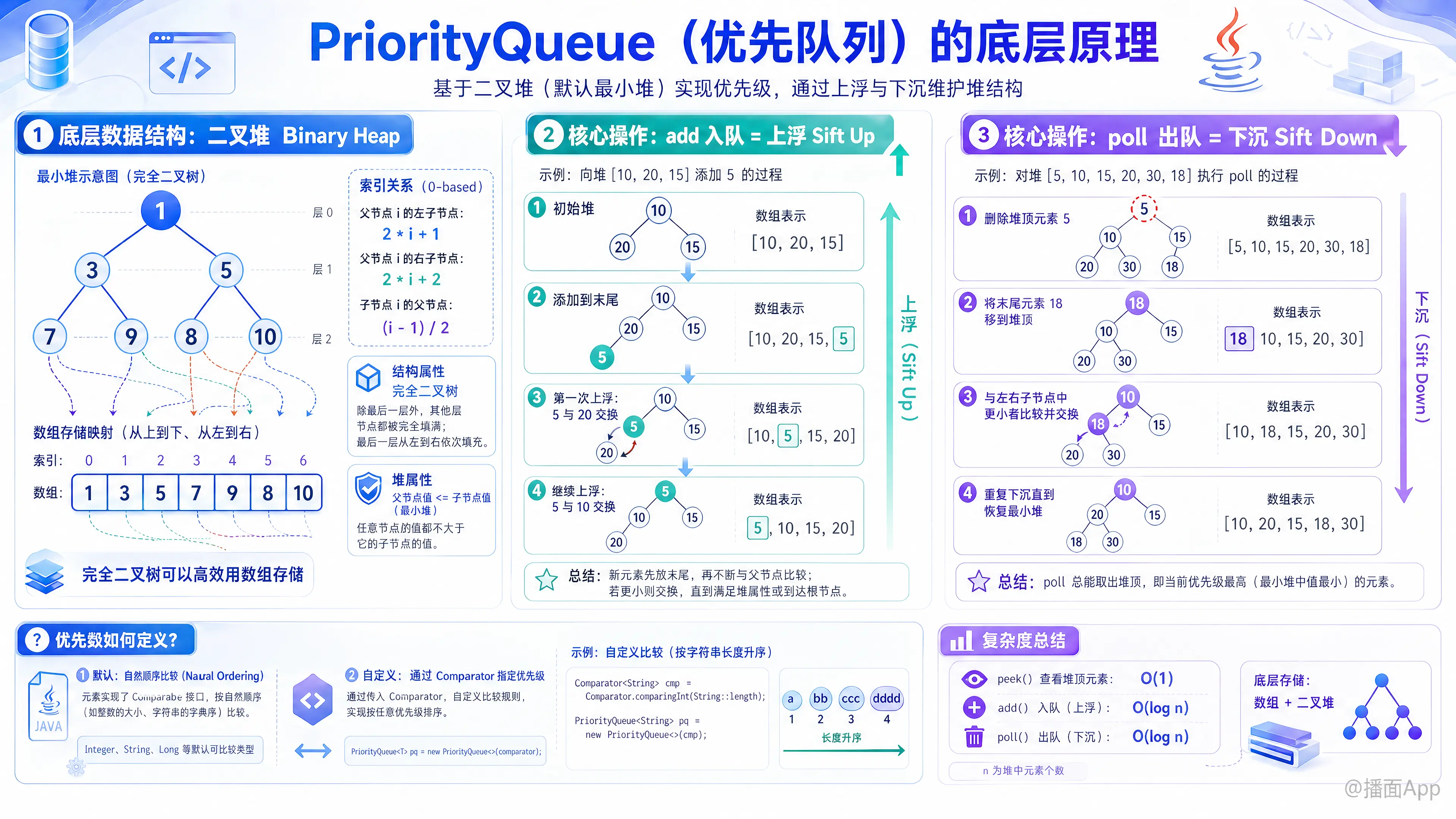
PriorityQueue 依靠底层二叉堆(默认最小堆)实现优先级。通过“上浮”(添加时)和“下沉”(删除时)算法维护堆结构,确保队首始终是最高优先级元素。
这是一个非常核心且重要的数据结构问题。
PriorityQueue(优先队列)实现其“优先级”的核心在于它底层使用了一种特殊的数据结构——二叉堆(Binary Heap)。
简单来说,你可以分三步来理解:
- 底层数据结构:它用的是什么?
- 核心操作:如何通过操作这个结构来维持优先级?
- 优先级定义:它怎么知道谁的优先级更高?
1. 底层数据结构:二叉堆(Binary Heap)
Java 的 PriorityQueue 默认实现是一个最小堆(Min-Heap)。堆是一种特殊的完全二叉树,它满足两个关键属性:
结构属性(Shape Property):它是一棵完全二叉树。这意味着树的每一层都是满的,除了最后一层,最后一层的节点都尽可能地靠左排列。这个特性使得我们可以非常高效地用数组来存储它,而不需要像普通树那样使用指针。
- 父节点索引
i的左子节点索引是2*i + 1 - 父节点索引
i的右子节点索引是2*i + 2 - 子节点索引
i的父节点索引是(i - 1) / 2
- 父节点索引
堆属性(Heap Property):对于最小堆来说,任何一个父节点的值都小于或等于其所有子节点的值。这意味着,树的根节点(数组的第一个元素)永远是整个队列中值最小(优先级最高)的元素。
上图是一个最小堆,根节点1是最小的元素。
2. 核心操作:如何维持优先级?
PriorityQueue 的主要操作是 add (入队) 和 poll (出队)。正是这两个操作的内部算法,保证了堆的属性始终被维持,从而实现了优先级。
a) add(E e) 方法(入队操作)
当一个新元素被添加到队列中时,为了不破坏堆的结构,它会经历一个“上浮”(Sift Up / Bubble Up)的过程:
- 添加到末尾:将新元素放在数组的末尾,这保持了完全二叉树的结构。
- 比较并上浮:将新元素与其父节点进行比较。如果新元素比父节点小(在最小堆中),就与父节点交换位置。
- 重复上浮:重复步骤2,直到这个新元素不再小于其父节点,或者它已经到达了堆顶(根节点)的位置。
示例:向 [10, 20, 15] 组成的堆中添加元素 5
初始状态:
- 数组:
[10, 20, 15] - 堆结构:plaintext
10 / \ 20 15
- 数组:
添加
5到末尾:- 数组:
[10, 20, 15, 5] - 堆结构:plaintext
10 / \ 20 15 / 5
此时,堆属性被破坏了(
5<20)。- 数组:
上浮
5:5和它的父节点20比较,5 < 20,交换。- 数组:
[10, 5, 15, 20] - 堆结构:plaintext
10 / \ 5 15 / 20
此时,堆属性仍然被破坏(
5<10)。继续上浮
5:5和它的新父节点10比较,5 < 10,交换。- 数组:
[5, 10, 15, 20] - 堆结构:plaintext
5 / \ 10 15 / 20
5到达了堆顶,上浮结束。堆属性恢复。
这个上浮过程的时间复杂度是 O(log n),因为树的高度是对数级别的。
b) poll() 方法(出队操作)
poll() 方法总是移除并返回优先级最高的元素,也就是堆顶的元素。为了保持堆的结构,它会经历一个“下沉”(Sift Down / Heapify)的过程:
- 记录并替换堆顶:记录下堆顶元素(数组的第一个元素),这是要返回的值。然后,将数组的最后一个元素移动到堆顶位置。这保证了树的完整性。
- 比较并下沉:将新的堆顶元素与其两个子节点中较小的一个进行比较。如果它比这个较小的子节点大,就与这个子节点交换位置。
- 重复下沉:重复步骤2,直到这个元素不再大于它的任何子节点,或者它已经到达了叶子节点的位置。
示例:从 [5, 10, 15, 20] 组成的堆中 poll() 元素
初始状态:
- 数组:
[5, 10, 15, 20] - 堆结构:plaintext
5 / \ 10 15 / 20
- 数组:
移除
5,用末尾元素20替换:- 要返回的值是
5。 - 数组变为:
[20, 10, 15] - 堆结构:plaintext
20 / \ 10 15
此时,堆属性被破坏(
20>10且20>15)。- 要返回的值是
下沉
20:20的子节点是10和15。较小的是10。20 > 10,所以20和10交换。- 数组:
[10, 20, 15] - 堆结构:plaintext
10 / \ 20 15
20现在是叶子节点,下沉结束。堆属性恢复。
这个下沉过程的时间复杂度也是 O(log n)。
3. 优先级定义:如何比较元素?
PriorityQueue 怎么知道哪个元素“更小”或“更大”呢?它通过以下两种方式之一来确定元素的优先级顺序:
自然排序 (Natural Ordering)
如果存入队列的元素类实现了java.lang.Comparable接口(例如Integer,String等),PriorityQueue会默认使用该类自身的compareTo()方法来比较元素。这就是所谓的自然排序。自定义排序 (Custom Ordering)
如果你想使用自定义的优先级规则(比如创建一个最大堆,或者根据对象的某个特定属性排序),可以在创建PriorityQueue时传入一个java.util.Comparator对象。示例:创建一个最大堆(优先级最高的元素是最大的)
java// 使用 Lambda 表达式创建一个比较器,实现降序排列 Comparator<Integer> maxHeapComparator = (a, b) -> b - a; // 或者使用现成的比较器 // Comparator<Integer> maxHeapComparator = Collections.reverseOrder(); PriorityQueue<Integer> maxHeap = new PriorityQueue<>(maxHeapComparator); maxHeap.add(10); maxHeap.add(30); maxHeap.add(20); System.out.println(maxHeap.peek()); // 输出 30,因为 30 是最大的元素
总结
| 特性 | 实现方式 |
|---|---|
| 底层数据结构 | 二叉堆(默认是最小堆),用数组高效存储。 |
| 核心算法 | add 操作通过 “上浮” (siftUp) 维持堆属性。poll 操作通过 “下沉” (siftDown) 维持堆属性。 |
| 优先级确定 | 通过元素的自然排序 (Comparable) 或在构造时传入的自定义比较器 (Comparator)。 |
| 时间复杂度 | add, poll: O(log n)peek (查看最高优先级元素): O(1) |
总而言之,PriorityQueue 通过在数组上巧妙地实现二叉堆数据结构,并利用上浮和下沉算法,在 O(log n) 的高效时间内完成了元素的插入和删除,同时始终确保队列的“头部”就是优先级最高的那个元素。