Redis 缓存穿透、击穿、雪崩
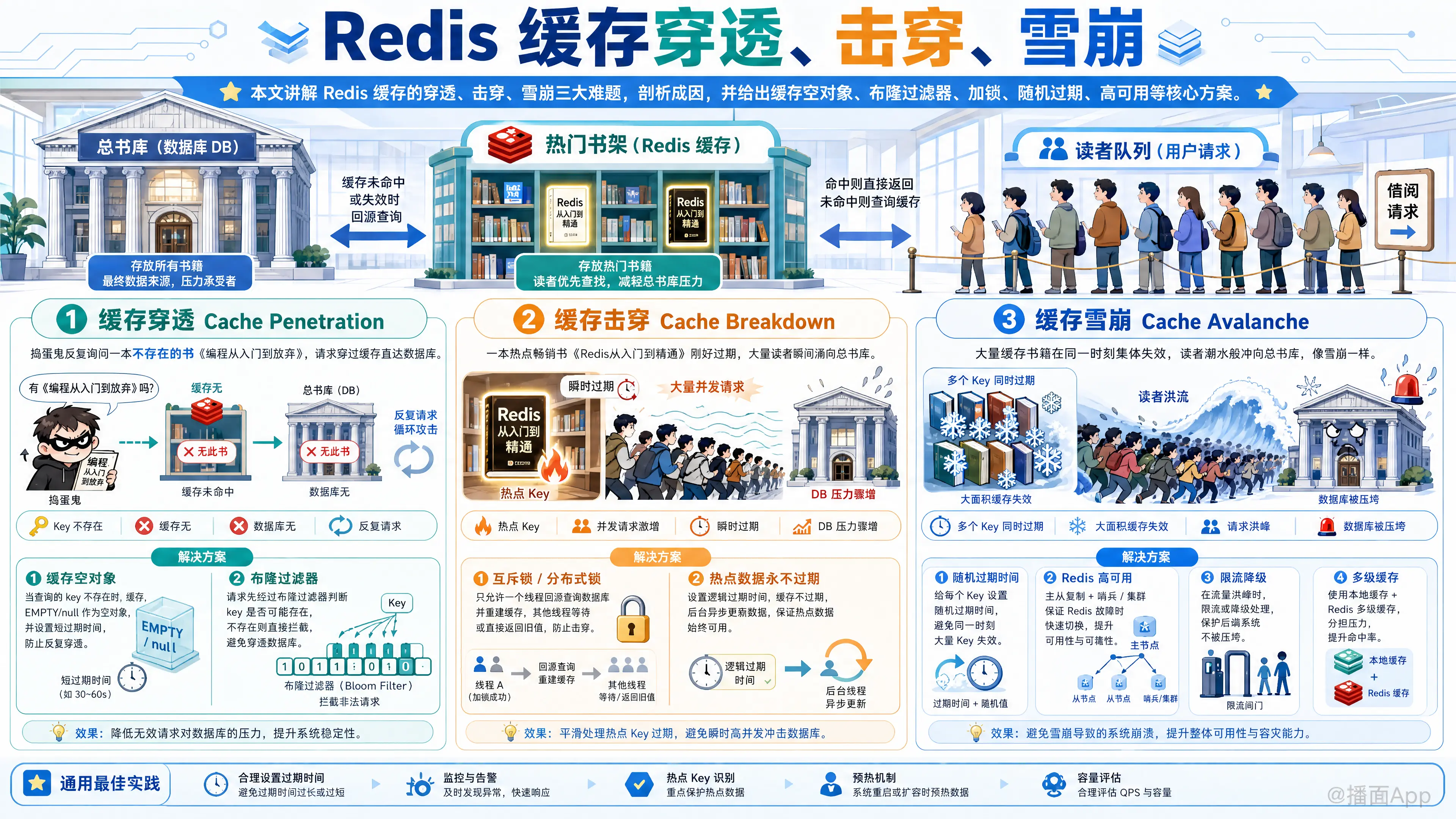
本文讲解了Redis缓存的穿透、击穿、雪崩三大难题,深入剖析了它们的成因,并提供了如缓存空对象、加锁、设置随机过期时间等一系列核心解决方案。
这是一个非常经典也是非常重要的 Redis/缓存面试题和知识点。我会用通俗易懂的方式,结合比喻来解释这三个问题以及它们的解决方案。
想象一下你的系统是一家非常火爆的图书馆:
- 数据库 (DB):是图书馆的 总书库,存放着所有的书籍,但查找和取书比较慢。
- Redis 缓存:是图书馆的 “热门书架”,放在最显眼的位置,读者常借的书都在这里,拿取非常快。
- 用户请求:就是来借书的 读者。
正常情况下,读者先去“热门书架”(缓存)找书,找到了就直接拿走,非常快。如果找不到,图书管理员再去“总书库”(数据库)里费力地把书找出来,交给读者,并把这本书的复本放到“热门书架”上,方便下一位读者。
1. 缓存穿透 (Cache Penetration)
什么是缓存穿透?
定义:指查询一个根本不存在的数据。由于缓存中没有(肯定没有),就会去数据库查询,数据库也查不到,所以不会写入缓存。这导致每次对这个不存在的数据的请求都会直接打到数据库上,就像“穿过”了缓存一样。
比喻:一个捣蛋鬼故意反复问图书管理员:“请问有《编程从入门到放弃》这本书吗?”
- 管理员先去“热门书架”(缓存)找,没有。
- 管理员又去“总书库”(数据库)找,也没有这本书。
- 管理员只好告诉捣蛋鬼:“没有这本书”。
- 捣蛋鬼不罢休,过一会又来问同样的问题。每一次,管理员都得重复上面两个无效的查找步骤。
如果有一大群捣蛋鬼(恶意攻击)都来问这本不存在的书,图书管理员(数据库)就会被大量无意义的查询请求累垮。
如何解决?
缓存空对象 (Cache Null Objects)
- 做法:当数据库查询返回为空时,我们仍然在缓存中为这个 key 存一个特殊的值(比如
null或者一个约定的字符串如"EMPTY"),并设置一个较短的过期时间。 - 优点:实现简单,效果好。后续请求这个不存在的 key 时,会直接从缓存中获取到这个“空值”,从而避免了对数据库的再次攻击。
- 缺点:需要消耗一些缓存空间;可能存在数据短期不一致的问题(如果在这期间数据库中又创建了这条数据)。
- 做法:当数据库查询返回为空时,我们仍然在缓存中为这个 key 存一个特殊的值(比如
布隆过滤器 (Bloom Filter)
- 做法:在访问缓存和数据库之前,使用布隆过滤器来判断这个 key 是否可能存在。布隆过滤器是一种高效的数据结构,它可以告诉你“一个元素一定不存在”或者“一个元素可能存在”。
- 流程:
- 将所有可能存在的数据的 key 哈希到一个足够大的位图中。
- 当一个请求过来,先去布隆过滤器查询这个 key。
- 如果布隆过滤器判断 key 不存在,就直接拒绝请求,根本不会去查缓存和数据库。
- 如果判断 key 可能存在,再继续执行后续的缓存、数据库查询。
- 优点:内存占用少,查询效率极高,能有效拦截大量非法请求。
- 缺点:有一定的误判率(一个不存在的 key 可能会被误判为存在);无法删除元素。
2. 缓存击穿 (Cache Breakdown)
什么是缓存击穿?
定义:指一个热点 Key(访问非常频繁的数据)在某个时刻突然过期了,此时正好有大量的并发请求访问这个 Key,这些请求都会因为缓存失效而直接打到数据库上,从而导致数据库压力瞬间增大。
比喻:图书馆正在热推一本畅销书《Redis从入门到精通》,这本书被放在“热门书架”(缓存)上,并且规定只能放1小时。
- 在这一小时内,所有来借这本书的读者都能从“热门书架”上快速拿到。
- 在 10:00:00 这一刻,这本书的展示时间到了,管理员把它从“热门书架”上拿走了(缓存过期)。
- 在 10:00:01 这一瞬间,突然来了 1000 个读者都指名要借这本书。
- 因为“热门书架”上没有了,这 1000 个读者请求都涌向了图书管理员,要求他去“总书库”(数据库)里找。这一个请求就把数据库压垮了。
缓存击穿的关键在于 “单个热点 Key” + “高并发”。
如何解决?
设置热点数据永不过期
- 做法:对于一些极度热门的数据(如首页配置、关键用户信息),可以直接在 Redis 中设置为永不过期。或者采用“逻辑过期”的策略,即在 value 中包含一个过期时间戳,由一个后台任务来异步更新缓存,而不是依赖 Redis 自带的过期机制。
- 优点:简单粗暴,能保证数据一直在缓存中。
- 缺点:不适用于所有数据,且需要维护数据的一致性。
使用互斥锁/分布式锁 (Mutex Lock)
- 做法:这是最经典的解决方案。当缓存失效时,不是让所有请求都去查数据库,而是只让第一个请求去查。这个请求在查数据库之前,先获取一个互斥锁。
- 流程:
- 线程 A 发现缓存失效,获取锁成功。
- 线程 A 去数据库查询数据,并将结果写入缓存。
- 写入缓存后,释放锁。
- 在线程 A 执行期间,其他线程(B、C、D)发现缓存失效,尝试获取锁,但失败了。它们不会去查数据库,而是进入等待或者休眠状态,然后过一会再重试(这个过程也叫自旋)。
- 当线程 A 释放锁后,其他线程再次尝试访问时,就可以直接从缓存中获取数据了。
- 优点:有效防止了数据库被高并发请求打垮,保证了数据一致性。
- 缺点:增加了系统复杂度,需要引入锁机制,可能会因为线程等待而降低一点吞吐量。
3. 缓存雪崩 (Cache Avalanche)
什么是缓存雪崩?
定义:指在某一时间段,缓存中大量的 Key 同时集中过期,或者 Redis 服务自身宕机。这导致大量的请求无法在缓存中处理,全部直接转发到数据库,造成数据库压力剧增,甚至宕机。
比喻:图书馆的“热门书架”(缓存)上的所有书籍都设置了在中午 12:00 准时下架(大量 Key 同时过期)。或者,更糟的是,整个“热门书架”突然塌了(Redis 宕机)。
- 到了 12:00,所有读者发现“热门书架”空了,于是所有人都涌向了图书管理员,要求从“总书库”(数据库)取书。
- 或者书架塌了,情况也是一样。
- 结果就是,数据库在短时间内收到了海量的、各种各样的查询请求,瞬间崩溃。
缓存雪崩的关键在于 “大面积” 或 “整体” 失效。
如何解决?
针对大量 Key 同时过期:
- 给过期时间增加一个随机值
- 做法:在设置缓存的过期时间时,不要都设置成固定的值(比如
expire(key, 3600)),而是在基础时间上增加一个随机数(比如expire(key, 3600 + random(0, 600)))。 - 优点:非常简单,能有效打散 Key 的过期时间,避免集中失效。
- 做法:在设置缓存的过期时间时,不要都设置成固定的值(比如
针对 Redis 宕机:
- 构建高可用 Redis 集群
- 做法:使用 Redis Sentinel(哨兵模式)或 Redis Cluster(集群模式)来搭建主从复制和高可用架构。当主节点宕机后,可以自动切换到从节点,保证缓存服务持续可用。
- 优点:从根本上解决了单点故障问题。
- 缺点:架构复杂度更高。
作为兜底方案:
- 服务降级与熔断
- 做法:当检测到数据库压力过大或 Redis 连接不上时,可以启动预案。比如,暂时关闭某些非核心功能,或者直接返回一些默认的、预设的缓存数据,而不是继续请求数据库。当系统恢复正常后再取消降级。Hystrix 等熔断器框架就是为此设计的。
- 优点:是保护后端系统的最后一道防线,保证系统核心功能可用,不至于全站崩溃。
- 缺点:牺牲了一部分用户体验和数据时效性。
总结
| 问题类型 | 核心原因 | 表现形式 | 解决方案 |
|---|---|---|---|
| 缓存穿透 | 查询不存在的数据 | 大量请求绕过缓存,直击数据库,查询不存在的数据。 | 1. 缓存空对象 2. 布隆过滤器 |
| 缓存击穿 | 单个热点 Key 过期 | 在某个瞬间,大量并发请求同一个热点数据,都打到数据库。 | 1. 热点数据永不过期/逻辑过期 2. 加互斥锁/分布式锁 |
| 缓存雪崩 | 大量 Key 同时过期 或 Redis 宕机 | 在某个时间段,缓存大面积失效,所有请求涌向数据库。 | 1. 过期时间加随机值 2. 构建高可用 Redis 集群 3. 服务降级与熔断 |